Denoising Autoencoder#
pimmslearn - INFO Experiment 03 - Analysis of latent spaces and performance comparisions
Papermill script parameters:
# files and folders
# Datasplit folder with data for experiment
folder_experiment: str = 'runs/example'
folder_data: str = '' # specify data directory if needed
file_format: str = 'csv' # file format of create splits, default pickle (pkl)
# Machine parsed metadata from rawfile workflow
fn_rawfile_metadata: str = 'data/dev_datasets/HeLa_6070/files_selected_metadata_N50.csv'
# training
epochs_max: int = 50 # Maximum number of epochs
# early_stopping:bool = True # Wheather to use early stopping or not
patience: int = 25 # Patience for early stopping
batch_size: int = 64 # Batch size for training (and evaluation)
cuda: bool = True # Whether to use a GPU for training
# model
# Dimensionality of encoding dimension (latent space of model)
latent_dim: int = 25
# A underscore separated string of layers, '128_64' for the encoder, reverse will be use for decoder
hidden_layers: str = '512'
sample_idx_position: int = 0 # position of index which is sample ID
model: str = 'DAE' # model name
model_key: str = 'DAE' # potentially alternative key for model (grid search)
save_pred_real_na: bool = True # Save all predictions for missing values
# metadata -> defaults for metadata extracted from machine data
meta_date_col: str = None # date column in meta data
meta_cat_col: str = None # category column in meta data
# Parameters
model = "DAE"
latent_dim = 10
batch_size = 64
epochs_max = 300
hidden_layers = "64"
sample_idx_position = 0
cuda = False
save_pred_real_na = True
fn_rawfile_metadata = "https://raw.githubusercontent.com/RasmussenLab/njab/HEAD/docs/tutorial/data/alzheimer/meta.csv"
folder_experiment = "runs/alzheimer_study"
model_key = "DAE"
Some argument transformations
{'folder_experiment': 'runs/alzheimer_study',
'folder_data': '',
'file_format': 'csv',
'fn_rawfile_metadata': 'https://raw.githubusercontent.com/RasmussenLab/njab/HEAD/docs/tutorial/data/alzheimer/meta.csv',
'epochs_max': 300,
'patience': 25,
'batch_size': 64,
'cuda': False,
'latent_dim': 10,
'hidden_layers': '64',
'sample_idx_position': 0,
'model': 'DAE',
'model_key': 'DAE',
'save_pred_real_na': True,
'meta_date_col': None,
'meta_cat_col': None}
{'batch_size': 64,
'cuda': False,
'data': Path('runs/alzheimer_study/data'),
'epochs_max': 300,
'file_format': 'csv',
'fn_rawfile_metadata': 'https://raw.githubusercontent.com/RasmussenLab/njab/HEAD/docs/tutorial/data/alzheimer/meta.csv',
'folder_data': '',
'folder_experiment': Path('runs/alzheimer_study'),
'hidden_layers': [64],
'latent_dim': 10,
'meta_cat_col': None,
'meta_date_col': None,
'model': 'DAE',
'model_key': 'DAE',
'out_figures': Path('runs/alzheimer_study/figures'),
'out_folder': Path('runs/alzheimer_study'),
'out_metrics': Path('runs/alzheimer_study'),
'out_models': Path('runs/alzheimer_study'),
'out_preds': Path('runs/alzheimer_study/preds'),
'patience': 25,
'sample_idx_position': 0,
'save_pred_real_na': True}
Some naming conventions
Load data in long format#
pimmslearn.io.datasplits - INFO Loaded 'train_X' from file: runs/alzheimer_study/data/train_X.csv
pimmslearn.io.datasplits - INFO Loaded 'val_y' from file: runs/alzheimer_study/data/val_y.csv
pimmslearn.io.datasplits - INFO Loaded 'test_y' from file: runs/alzheimer_study/data/test_y.csv
data is loaded in long format
Sample ID protein groups
Sample_120 Q15223;Q15223-2;Q15223-3 18.655
Sample_191 P17405;P17405-4 13.281
Sample_139 K7ERI9;P02654 19.250
Sample_016 O95841 14.699
Sample_188 P18065 20.814
Name: intensity, dtype: float64
Infer index names from long format
pimmslearn - INFO sample_id = 'Sample ID', single feature: index_column = 'protein groups'
load meta data for splits
| _collection site | _age at CSF collection | _gender | _t-tau [ng/L] | _p-tau [ng/L] | _Abeta-42 [ng/L] | _Abeta-40 [ng/L] | _Abeta-42/Abeta-40 ratio | _primary biochemical AD classification | _clinical AD diagnosis | _MMSE score | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Sample ID | |||||||||||
| Sample_000 | Sweden | 71.000 | f | 703.000 | 85.000 | 562.000 | NaN | NaN | biochemical control | NaN | NaN |
| Sample_001 | Sweden | 77.000 | m | 518.000 | 91.000 | 334.000 | NaN | NaN | biochemical AD | NaN | NaN |
| Sample_002 | Sweden | 75.000 | m | 974.000 | 87.000 | 515.000 | NaN | NaN | biochemical AD | NaN | NaN |
| Sample_003 | Sweden | 72.000 | f | 950.000 | 109.000 | 394.000 | NaN | NaN | biochemical AD | NaN | NaN |
| Sample_004 | Sweden | 63.000 | f | 873.000 | 88.000 | 234.000 | NaN | NaN | biochemical AD | NaN | NaN |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| Sample_205 | Berlin | 69.000 | f | 1,945.000 | NaN | 699.000 | 12,140.000 | 0.058 | biochemical AD | AD | 17.000 |
| Sample_206 | Berlin | 73.000 | m | 299.000 | NaN | 1,420.000 | 16,571.000 | 0.086 | biochemical control | non-AD | 28.000 |
| Sample_207 | Berlin | 71.000 | f | 262.000 | NaN | 639.000 | 9,663.000 | 0.066 | biochemical control | non-AD | 28.000 |
| Sample_208 | Berlin | 83.000 | m | 289.000 | NaN | 1,436.000 | 11,285.000 | 0.127 | biochemical control | non-AD | 24.000 |
| Sample_209 | Berlin | 63.000 | f | 591.000 | NaN | 1,299.000 | 11,232.000 | 0.116 | biochemical control | non-AD | 29.000 |
210 rows × 11 columns
Produce some addional simulated samples#
The validation simulated NA is used to by all models to evaluate training performance.
| observed | ||
|---|---|---|
| Sample ID | protein groups | |
| Sample_158 | Q9UN70;Q9UN70-2 | 14.630 |
| Sample_050 | Q9Y287 | 15.755 |
| Sample_107 | Q8N475;Q8N475-2 | 15.029 |
| Sample_199 | P06307 | 19.376 |
| Sample_067 | Q5VUB5 | 15.309 |
| ... | ... | ... |
| Sample_111 | F6SYF8;Q9UBP4 | 22.822 |
| Sample_002 | A0A0A0MT36 | 18.165 |
| Sample_049 | Q8WY21;Q8WY21-2;Q8WY21-3;Q8WY21-4 | 15.525 |
| Sample_182 | Q8NFT8 | 14.379 |
| Sample_123 | Q16853;Q16853-2 | 14.504 |
12600 rows × 1 columns
| observed | |
|---|---|
| count | 12,600.000 |
| mean | 16.339 |
| std | 2.741 |
| min | 7.209 |
| 25% | 14.412 |
| 50% | 15.935 |
| 75% | 17.910 |
| max | 30.140 |
Data in wide format#
Autoencoder need data in wide format
| protein groups | A0A024QZX5;A0A087X1N8;P35237 | A0A024R0T9;K7ER74;P02655 | A0A024R3W6;A0A024R412;O60462;O60462-2;O60462-3;O60462-4;O60462-5;Q7LBX6;X5D2Q8 | A0A024R644;A0A0A0MRU5;A0A1B0GWI2;O75503 | A0A075B6H7 | A0A075B6H9 | A0A075B6I0 | A0A075B6I1 | A0A075B6I6 | A0A075B6I9 | ... | Q9Y653;Q9Y653-2;Q9Y653-3 | Q9Y696 | Q9Y6C2 | Q9Y6N6 | Q9Y6N7;Q9Y6N7-2;Q9Y6N7-4 | Q9Y6R7 | Q9Y6X5 | Q9Y6Y8;Q9Y6Y8-2 | Q9Y6Y9 | S4R3U6 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sample ID | |||||||||||||||||||||
| Sample_000 | 15.912 | 16.852 | 15.570 | 16.481 | 17.301 | 20.246 | 16.764 | 17.584 | 16.988 | 20.054 | ... | 16.012 | 15.178 | NaN | 15.050 | 16.842 | NaN | NaN | 19.563 | NaN | 12.805 |
| Sample_001 | NaN | 16.874 | 15.519 | 16.387 | NaN | 19.941 | 18.786 | 17.144 | NaN | 19.067 | ... | 15.528 | 15.576 | NaN | 14.833 | 16.597 | 20.299 | 15.556 | 19.386 | 13.970 | 12.442 |
| Sample_002 | 16.111 | NaN | 15.935 | 16.416 | 18.175 | 19.251 | 16.832 | 15.671 | 17.012 | 18.569 | ... | 15.229 | 14.728 | 13.757 | 15.118 | 17.440 | 19.598 | 15.735 | 20.447 | 12.636 | 12.505 |
| Sample_003 | 16.107 | 17.032 | 15.802 | 16.979 | 15.963 | 19.628 | 17.852 | 18.877 | 14.182 | 18.985 | ... | 15.495 | 14.590 | 14.682 | 15.140 | 17.356 | 19.429 | NaN | 20.216 | NaN | 12.445 |
| Sample_004 | 15.603 | 15.331 | 15.375 | 16.679 | NaN | 20.450 | 18.682 | 17.081 | 14.140 | 19.686 | ... | 14.757 | NaN | NaN | 15.256 | 17.075 | 19.582 | 15.328 | NaN | 13.145 | NaN |
5 rows × 1421 columns
Fill Validation data with potentially missing features#
| protein groups | A0A024QZX5;A0A087X1N8;P35237 | A0A024R0T9;K7ER74;P02655 | A0A024R3W6;A0A024R412;O60462;O60462-2;O60462-3;O60462-4;O60462-5;Q7LBX6;X5D2Q8 | A0A024R644;A0A0A0MRU5;A0A1B0GWI2;O75503 | A0A075B6H7 | A0A075B6H9 | A0A075B6I0 | A0A075B6I1 | A0A075B6I6 | A0A075B6I9 | ... | Q9Y653;Q9Y653-2;Q9Y653-3 | Q9Y696 | Q9Y6C2 | Q9Y6N6 | Q9Y6N7;Q9Y6N7-2;Q9Y6N7-4 | Q9Y6R7 | Q9Y6X5 | Q9Y6Y8;Q9Y6Y8-2 | Q9Y6Y9 | S4R3U6 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sample ID | |||||||||||||||||||||
| Sample_000 | 15.912 | 16.852 | 15.570 | 16.481 | 17.301 | 20.246 | 16.764 | 17.584 | 16.988 | 20.054 | ... | 16.012 | 15.178 | NaN | 15.050 | 16.842 | NaN | NaN | 19.563 | NaN | 12.805 |
| Sample_001 | NaN | 16.874 | 15.519 | 16.387 | NaN | 19.941 | 18.786 | 17.144 | NaN | 19.067 | ... | 15.528 | 15.576 | NaN | 14.833 | 16.597 | 20.299 | 15.556 | 19.386 | 13.970 | 12.442 |
| Sample_002 | 16.111 | NaN | 15.935 | 16.416 | 18.175 | 19.251 | 16.832 | 15.671 | 17.012 | 18.569 | ... | 15.229 | 14.728 | 13.757 | 15.118 | 17.440 | 19.598 | 15.735 | 20.447 | 12.636 | 12.505 |
| Sample_003 | 16.107 | 17.032 | 15.802 | 16.979 | 15.963 | 19.628 | 17.852 | 18.877 | 14.182 | 18.985 | ... | 15.495 | 14.590 | 14.682 | 15.140 | 17.356 | 19.429 | NaN | 20.216 | NaN | 12.445 |
| Sample_004 | 15.603 | 15.331 | 15.375 | 16.679 | NaN | 20.450 | 18.682 | 17.081 | 14.140 | 19.686 | ... | 14.757 | NaN | NaN | 15.256 | 17.075 | 19.582 | 15.328 | NaN | 13.145 | NaN |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| Sample_205 | 15.682 | 16.886 | 14.910 | 16.482 | NaN | 17.705 | 17.039 | NaN | 16.413 | 19.102 | ... | NaN | 15.684 | 14.236 | 15.415 | 17.551 | 17.922 | 16.340 | 19.928 | 12.929 | NaN |
| Sample_206 | 15.798 | 17.554 | 15.600 | 15.938 | NaN | 18.154 | 18.152 | 16.503 | 16.860 | 18.538 | ... | 15.422 | 16.106 | NaN | 15.345 | 17.084 | 18.708 | NaN | 19.433 | NaN | NaN |
| Sample_207 | 15.739 | NaN | 15.469 | 16.898 | NaN | 18.636 | 17.950 | 16.321 | 16.401 | 18.849 | ... | 15.808 | 16.098 | 14.403 | 15.715 | NaN | 18.725 | 16.138 | 19.599 | 13.637 | 11.174 |
| Sample_208 | 15.477 | 16.779 | 14.995 | 16.132 | NaN | 14.908 | NaN | NaN | 16.119 | 18.368 | ... | 15.157 | 16.712 | NaN | 14.640 | 16.533 | 19.411 | 15.807 | 19.545 | NaN | NaN |
| Sample_209 | NaN | 17.261 | 15.175 | 16.235 | NaN | 17.893 | 17.744 | 16.371 | 15.780 | 18.806 | ... | 15.237 | 15.652 | 15.211 | 14.205 | 16.749 | 19.275 | 15.732 | 19.577 | 11.042 | 11.791 |
210 rows × 1421 columns
| protein groups | A0A024QZX5;A0A087X1N8;P35237 | A0A024R0T9;K7ER74;P02655 | A0A024R3W6;A0A024R412;O60462;O60462-2;O60462-3;O60462-4;O60462-5;Q7LBX6;X5D2Q8 | A0A024R644;A0A0A0MRU5;A0A1B0GWI2;O75503 | A0A075B6H7 | A0A075B6H9 | A0A075B6I0 | A0A075B6I1 | A0A075B6I6 | A0A075B6I9 | ... | Q9Y653;Q9Y653-2;Q9Y653-3 | Q9Y696 | Q9Y6C2 | Q9Y6N6 | Q9Y6N7;Q9Y6N7-2;Q9Y6N7-4 | Q9Y6R7 | Q9Y6X5 | Q9Y6Y8;Q9Y6Y8-2 | Q9Y6Y9 | S4R3U6 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sample ID | |||||||||||||||||||||
| Sample_000 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | 19.863 | NaN | NaN | NaN | NaN |
| Sample_001 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| Sample_002 | NaN | 14.523 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| Sample_003 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| Sample_004 | NaN | NaN | NaN | NaN | 15.473 | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | 14.048 | NaN | NaN | NaN | NaN | 19.867 | NaN | 12.235 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| Sample_205 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 11.802 |
| Sample_206 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| Sample_207 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| Sample_208 | NaN | NaN | NaN | NaN | NaN | NaN | 17.530 | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| Sample_209 | 15.727 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
210 rows × 1419 columns
| protein groups | A0A024QZX5;A0A087X1N8;P35237 | A0A024R0T9;K7ER74;P02655 | A0A024R3W6;A0A024R412;O60462;O60462-2;O60462-3;O60462-4;O60462-5;Q7LBX6;X5D2Q8 | A0A024R644;A0A0A0MRU5;A0A1B0GWI2;O75503 | A0A075B6H7 | A0A075B6H9 | A0A075B6I0 | A0A075B6I1 | A0A075B6I6 | A0A075B6I9 | ... | Q9Y653;Q9Y653-2;Q9Y653-3 | Q9Y696 | Q9Y6C2 | Q9Y6N6 | Q9Y6N7;Q9Y6N7-2;Q9Y6N7-4 | Q9Y6R7 | Q9Y6X5 | Q9Y6Y8;Q9Y6Y8-2 | Q9Y6Y9 | S4R3U6 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sample ID | |||||||||||||||||||||
| Sample_000 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | 19.863 | NaN | NaN | NaN | NaN |
| Sample_001 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| Sample_002 | NaN | 14.523 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| Sample_003 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| Sample_004 | NaN | NaN | NaN | NaN | 15.473 | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | 14.048 | NaN | NaN | NaN | NaN | 19.867 | NaN | 12.235 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| Sample_205 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 11.802 |
| Sample_206 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| Sample_207 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| Sample_208 | NaN | NaN | NaN | NaN | NaN | NaN | 17.530 | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| Sample_209 | 15.727 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
210 rows × 1421 columns
Denoising Autoencoder#
Analysis: DataLoaders, Model, transform#
Autoencoder(
(encoder): Sequential(
(0): Linear(in_features=1421, out_features=64, bias=True)
(1): Dropout(p=0.2, inplace=False)
(2): BatchNorm1d(64, eps=1e-05, momentum=0.1, affine=True, bias=True, track_running_stats=True)
(3): LeakyReLU(negative_slope=0.1)
(4): Linear(in_features=64, out_features=10, bias=True)
)
(decoder): Sequential(
(0): Linear(in_features=10, out_features=64, bias=True)
(1): Dropout(p=0.2, inplace=False)
(2): BatchNorm1d(64, eps=1e-05, momentum=0.1, affine=True, bias=True, track_running_stats=True)
(3): LeakyReLU(negative_slope=0.1)
(4): Linear(in_features=64, out_features=1421, bias=True)
)
)
Training#
Start Fit
- before_fit : [TrainEvalCallback, Recorder, ProgressCallback, EarlyStoppingCallback]
Start Epoch Loop
- before_epoch : [Recorder, ProgressCallback]
Start Train
- before_train : [TrainEvalCallback, Recorder, ProgressCallback]
Start Batch Loop
- before_batch : [ModelAdapter, CastToTensor]
- after_pred : [ModelAdapter]
- after_loss : [ModelAdapter]
- before_backward: []
- before_step : []
- after_step : []
- after_cancel_batch: []
- after_batch : [TrainEvalCallback, Recorder, ProgressCallback]
End Batch Loop
End Train
- after_cancel_train: [Recorder]
- after_train : [Recorder, ProgressCallback]
Start Valid
- before_validate: [TrainEvalCallback, Recorder, ProgressCallback]
Start Batch Loop
- **CBs same as train batch**: []
End Batch Loop
End Valid
- after_cancel_validate: [Recorder]
- after_validate : [Recorder, ProgressCallback]
End Epoch Loop
- after_cancel_epoch: []
- after_epoch : [Recorder, EarlyStoppingCallback]
End Fit
- after_cancel_fit: []
- after_fit : [ProgressCallback, EarlyStoppingCallback]
Adding a EarlyStoppingCallback results in an error. Potential fix in
PR3509 is not yet in
current version. Try again later
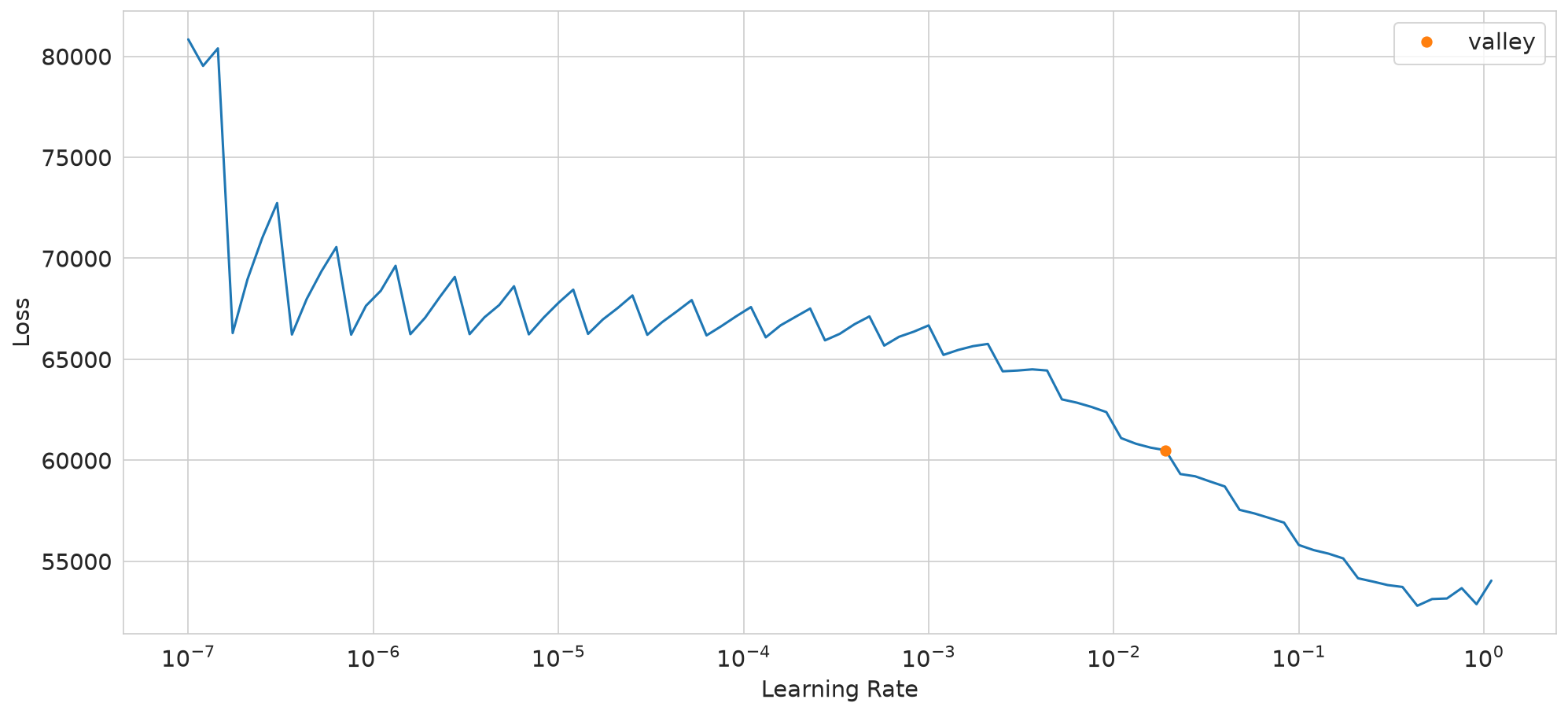
SuggestedLRs(valley=0.019054606556892395)
dump model config
| epoch | train_loss | valid_loss | time |
|---|---|---|---|
| 0 | 65174.800781 | 4034.468994 | 00:00 |
| 1 | 63549.527344 | 4026.505127 | 00:00 |
| 2 | 62116.339844 | 3987.944580 | 00:00 |
| 3 | 60740.785156 | 3891.825684 | 00:00 |
| 4 | 59400.671875 | 3767.303467 | 00:00 |
| 5 | 58062.488281 | 3627.985352 | 00:00 |
| 6 | 56741.464844 | 3488.158936 | 00:00 |
| 7 | 55437.988281 | 3365.538086 | 00:00 |
| 8 | 54154.250000 | 3259.773193 | 00:00 |
| 9 | 52908.339844 | 3170.856934 | 00:00 |
| 10 | 51727.382812 | 3098.698486 | 00:00 |
| 11 | 50624.257812 | 3057.018799 | 00:00 |
| 12 | 49543.621094 | 3001.542969 | 00:00 |
| 13 | 48541.738281 | 2941.308350 | 00:00 |
| 14 | 47581.355469 | 2875.419678 | 00:00 |
| 15 | 46713.667969 | 2800.025635 | 00:00 |
| 16 | 45873.722656 | 2730.840820 | 00:00 |
| 17 | 45041.089844 | 2676.259277 | 00:00 |
| 18 | 44252.777344 | 2625.450684 | 00:00 |
| 19 | 43481.054688 | 2577.369629 | 00:00 |
| 20 | 42720.058594 | 2542.479248 | 00:00 |
| 21 | 42018.332031 | 2517.842529 | 00:00 |
| 22 | 41324.316406 | 2489.821045 | 00:00 |
| 23 | 40692.339844 | 2457.643555 | 00:00 |
| 24 | 40057.683594 | 2438.637451 | 00:00 |
| 25 | 39470.500000 | 2428.357666 | 00:00 |
| 26 | 38915.855469 | 2423.570801 | 00:00 |
| 27 | 38378.652344 | 2412.010498 | 00:00 |
| 28 | 37858.914062 | 2400.558594 | 00:00 |
| 29 | 37353.968750 | 2390.109619 | 00:00 |
| 30 | 36899.546875 | 2361.311523 | 00:00 |
| 31 | 36416.312500 | 2350.252930 | 00:00 |
| 32 | 35986.566406 | 2337.663330 | 00:00 |
| 33 | 35595.175781 | 2316.374268 | 00:00 |
| 34 | 35194.531250 | 2307.196777 | 00:00 |
| 35 | 34792.101562 | 2335.916992 | 00:00 |
| 36 | 34438.804688 | 2320.223633 | 00:00 |
| 37 | 34096.378906 | 2303.182861 | 00:00 |
| 38 | 33757.457031 | 2302.162598 | 00:00 |
| 39 | 33397.917969 | 2316.916260 | 00:00 |
| 40 | 33072.914062 | 2303.244141 | 00:00 |
| 41 | 32795.191406 | 2290.052490 | 00:00 |
| 42 | 32484.744141 | 2272.879639 | 00:00 |
| 43 | 32211.939453 | 2315.419922 | 00:00 |
| 44 | 31920.509766 | 2309.465332 | 00:00 |
| 45 | 31631.513672 | 2275.872559 | 00:00 |
| 46 | 31378.757812 | 2278.935059 | 00:00 |
| 47 | 31147.990234 | 2297.382324 | 00:00 |
| 48 | 30924.755859 | 2302.321533 | 00:00 |
| 49 | 30744.029297 | 2315.240234 | 00:00 |
| 50 | 30540.240234 | 2308.348877 | 00:00 |
| 51 | 30318.468750 | 2320.664795 | 00:00 |
| 52 | 30122.714844 | 2296.704102 | 00:00 |
| 53 | 29963.548828 | 2340.302002 | 00:00 |
| 54 | 29819.492188 | 2328.722168 | 00:00 |
| 55 | 29702.976562 | 2321.131836 | 00:00 |
| 56 | 29555.021484 | 2308.097168 | 00:00 |
| 57 | 29481.712891 | 2362.730225 | 00:00 |
| 58 | 29412.343750 | 2303.982666 | 00:00 |
| 59 | 29269.449219 | 2303.622070 | 00:00 |
| 60 | 29117.392578 | 2271.735352 | 00:00 |
| 61 | 28999.470703 | 2274.403320 | 00:00 |
| 62 | 28882.281250 | 2335.160889 | 00:00 |
| 63 | 28819.591797 | 2314.614258 | 00:00 |
| 64 | 28704.718750 | 2323.729736 | 00:00 |
| 65 | 28632.257812 | 2271.978760 | 00:00 |
| 66 | 28524.222656 | 2272.674072 | 00:00 |
| 67 | 28439.078125 | 2244.347168 | 00:00 |
| 68 | 28327.439453 | 2256.835449 | 00:00 |
| 69 | 28284.953125 | 2255.192871 | 00:00 |
| 70 | 28179.125000 | 2223.358398 | 00:00 |
| 71 | 28063.787109 | 2246.650635 | 00:00 |
| 72 | 27969.136719 | 2220.927002 | 00:00 |
| 73 | 27866.787109 | 2246.438721 | 00:00 |
| 74 | 27748.447266 | 2235.906494 | 00:00 |
| 75 | 27659.523438 | 2264.310791 | 00:00 |
| 76 | 27578.390625 | 2235.760498 | 00:00 |
| 77 | 27470.394531 | 2233.545898 | 00:00 |
| 78 | 27412.933594 | 2205.119385 | 00:00 |
| 79 | 27316.449219 | 2227.448242 | 00:00 |
| 80 | 27273.919922 | 2204.467041 | 00:00 |
| 81 | 27221.261719 | 2203.687256 | 00:00 |
| 82 | 27189.964844 | 2229.575928 | 00:00 |
| 83 | 27155.085938 | 2257.994873 | 00:00 |
| 84 | 27089.582031 | 2240.178467 | 00:00 |
| 85 | 27058.355469 | 2267.365967 | 00:00 |
| 86 | 26978.726562 | 2222.660889 | 00:00 |
| 87 | 26883.527344 | 2218.987549 | 00:00 |
| 88 | 26845.796875 | 2217.701416 | 00:00 |
| 89 | 26755.013672 | 2223.526123 | 00:00 |
| 90 | 26645.197266 | 2233.115479 | 00:00 |
| 91 | 26587.742188 | 2238.161621 | 00:00 |
| 92 | 26548.587891 | 2260.156738 | 00:00 |
| 93 | 26545.070312 | 2190.558838 | 00:00 |
| 94 | 26517.296875 | 2205.640869 | 00:00 |
| 95 | 26502.144531 | 2219.470459 | 00:00 |
| 96 | 26476.521484 | 2187.347412 | 00:00 |
| 97 | 26443.935547 | 2229.598389 | 00:00 |
| 98 | 26407.738281 | 2218.359863 | 00:00 |
| 99 | 26338.927734 | 2199.817383 | 00:00 |
| 100 | 26301.818359 | 2267.508545 | 00:00 |
| 101 | 26241.902344 | 2204.698975 | 00:00 |
| 102 | 26269.537109 | 2243.899902 | 00:00 |
| 103 | 26230.287109 | 2190.475098 | 00:00 |
| 104 | 26224.433594 | 2248.840088 | 00:00 |
| 105 | 26258.312500 | 2189.895996 | 00:00 |
| 106 | 26245.539062 | 2223.889893 | 00:00 |
| 107 | 26188.417969 | 2202.270020 | 00:00 |
| 108 | 26162.333984 | 2208.812744 | 00:00 |
| 109 | 26108.998047 | 2204.817627 | 00:00 |
| 110 | 26113.906250 | 2187.708984 | 00:00 |
| 111 | 26087.064453 | 2192.132568 | 00:00 |
| 112 | 26046.144531 | 2175.907959 | 00:00 |
| 113 | 26021.457031 | 2196.797119 | 00:00 |
| 114 | 25951.216797 | 2221.429443 | 00:00 |
| 115 | 25939.921875 | 2206.627197 | 00:00 |
| 116 | 25933.574219 | 2203.353027 | 00:00 |
| 117 | 25913.753906 | 2198.609131 | 00:00 |
| 118 | 25853.914062 | 2262.425049 | 00:00 |
| 119 | 25799.359375 | 2199.565430 | 00:00 |
| 120 | 25759.033203 | 2216.852539 | 00:00 |
| 121 | 25709.972656 | 2220.053711 | 00:00 |
| 122 | 25668.845703 | 2210.848145 | 00:00 |
| 123 | 25622.972656 | 2239.099365 | 00:00 |
| 124 | 25555.656250 | 2200.077881 | 00:00 |
| 125 | 25536.871094 | 2201.066162 | 00:00 |
| 126 | 25546.515625 | 2216.143555 | 00:00 |
| 127 | 25536.890625 | 2194.457764 | 00:00 |
| 128 | 25516.033203 | 2179.429443 | 00:00 |
| 129 | 25482.685547 | 2181.277344 | 00:00 |
| 130 | 25472.550781 | 2167.322998 | 00:00 |
| 131 | 25460.878906 | 2168.380615 | 00:00 |
| 132 | 25429.486328 | 2198.965820 | 00:00 |
| 133 | 25371.005859 | 2190.189697 | 00:00 |
| 134 | 25322.222656 | 2175.832520 | 00:00 |
| 135 | 25338.380859 | 2203.517822 | 00:00 |
| 136 | 25298.162109 | 2192.833008 | 00:00 |
| 137 | 25291.933594 | 2187.753662 | 00:00 |
| 138 | 25263.734375 | 2184.420898 | 00:00 |
| 139 | 25267.320312 | 2196.046631 | 00:00 |
| 140 | 25203.716797 | 2193.755127 | 00:00 |
| 141 | 25191.125000 | 2184.902832 | 00:00 |
| 142 | 25172.283203 | 2190.973877 | 00:00 |
| 143 | 25209.416016 | 2206.764648 | 00:00 |
| 144 | 25152.705078 | 2194.879883 | 00:00 |
| 145 | 25135.521484 | 2189.315674 | 00:00 |
| 146 | 25142.369141 | 2176.426758 | 00:00 |
| 147 | 25143.169922 | 2174.892334 | 00:00 |
| 148 | 25115.984375 | 2190.884521 | 00:00 |
| 149 | 25104.091797 | 2191.089844 | 00:00 |
| 150 | 25138.136719 | 2182.817383 | 00:00 |
| 151 | 25128.486328 | 2189.947998 | 00:00 |
| 152 | 25110.734375 | 2202.158691 | 00:00 |
| 153 | 25088.927734 | 2176.808105 | 00:00 |
| 154 | 25102.859375 | 2183.753662 | 00:00 |
| 155 | 25059.722656 | 2185.644775 | 00:00 |
No improvement since epoch 130: early stopping
Save number of actually trained epochs
156
Loss normalized by total number of measurements#
pimmslearn.plotting - INFO Saved Figures to runs/alzheimer_study/figures/dae_training
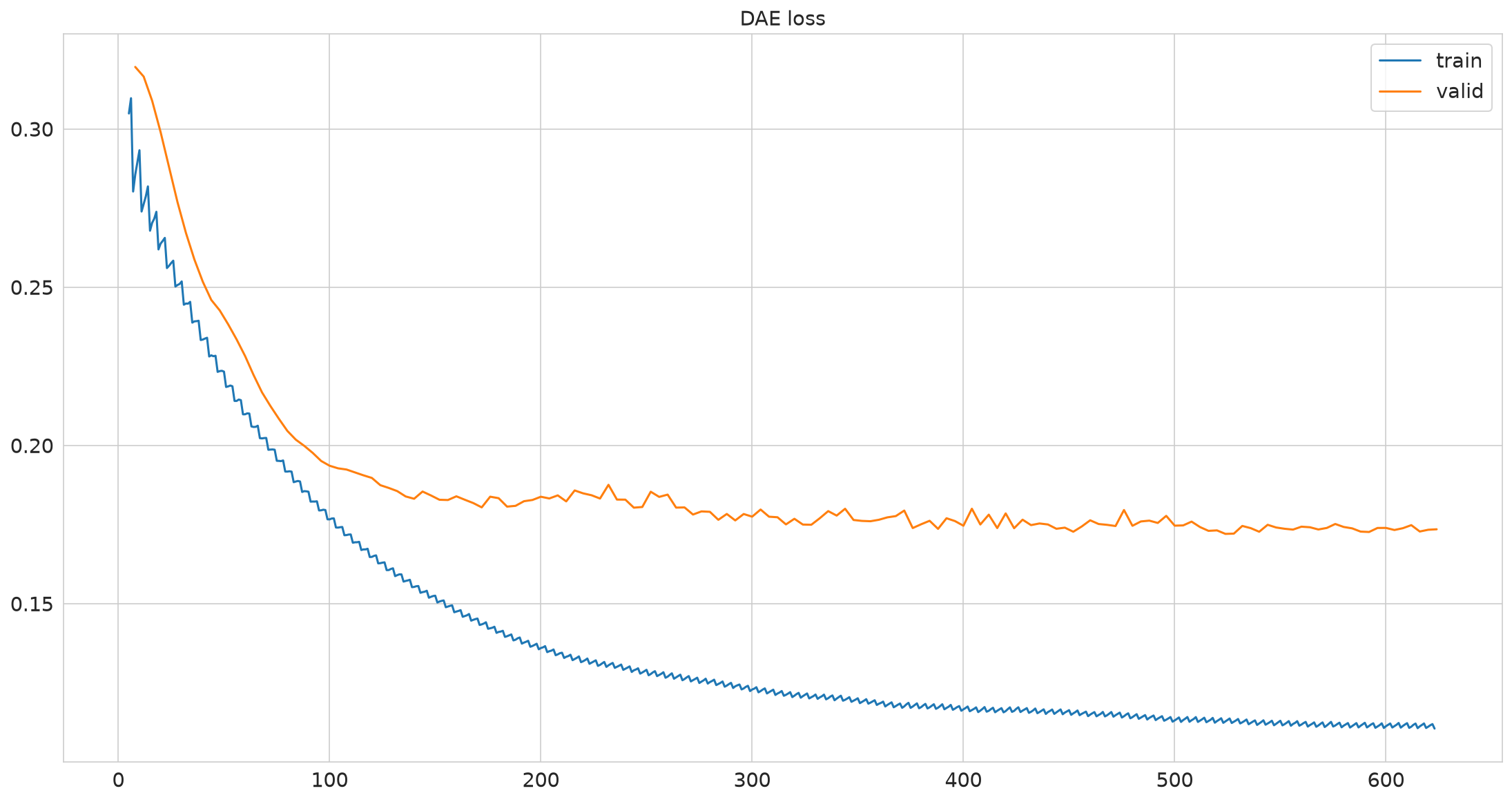
Why is the validation loss better then the training loss?
during training input data is masked and needs to be reconstructed
when evaluating the model, all input data is provided and only the artifically masked data is used for evaluation.
Predictions#
data of training data set and validation dataset to create predictions is the same as training data.
predictions include missing values (which are not further compared)
[ ] double check ModelAdapter
create predictiona and select for validation data
Sample ID protein groups
Sample_000 A0A024QZX5;A0A087X1N8;P35237 15.950
A0A024R0T9;K7ER74;P02655 16.734
A0A024R3W6;A0A024R412;O60462;O60462-2;O60462-3;O60462-4;O60462-5;Q7LBX6;X5D2Q8 15.732
A0A024R644;A0A0A0MRU5;A0A1B0GWI2;O75503 16.686
A0A075B6H7 16.228
...
Sample_209 Q9Y6R7 19.028
Q9Y6X5 15.644
Q9Y6Y8;Q9Y6Y8-2 19.347
Q9Y6Y9 11.450
S4R3U6 11.373
Length: 298410, dtype: float32
| observed | DAE | ||
|---|---|---|---|
| Sample ID | protein groups | ||
| Sample_158 | Q9UN70;Q9UN70-2 | 14.630 | 15.750 |
| Sample_050 | Q9Y287 | 15.755 | 17.023 |
| Sample_107 | Q8N475;Q8N475-2 | 15.029 | 13.672 |
| Sample_199 | P06307 | 19.376 | 18.925 |
| Sample_067 | Q5VUB5 | 15.309 | 15.290 |
| ... | ... | ... | ... |
| Sample_111 | F6SYF8;Q9UBP4 | 22.822 | 22.936 |
| Sample_002 | A0A0A0MT36 | 18.165 | 15.529 |
| Sample_049 | Q8WY21;Q8WY21-2;Q8WY21-3;Q8WY21-4 | 15.525 | 15.956 |
| Sample_182 | Q8NFT8 | 14.379 | 14.157 |
| Sample_123 | Q16853;Q16853-2 | 14.504 | 14.553 |
12600 rows × 2 columns
| observed | DAE | ||
|---|---|---|---|
| Sample ID | protein groups | ||
| Sample_000 | A0A075B6P5;P01615 | 17.016 | 17.122 |
| A0A087X089;Q16627;Q16627-2 | 18.280 | 18.151 | |
| A0A0B4J2B5;S4R460 | 21.735 | 22.467 | |
| A0A140T971;O95865;Q5SRR8;Q5SSV3 | 14.603 | 15.161 | |
| A0A140TA33;A0A140TA41;A0A140TA52;P22105;P22105-3;P22105-4 | 16.143 | 16.612 | |
| ... | ... | ... | ... |
| Sample_209 | Q96ID5 | 16.074 | 15.817 |
| Q9H492;Q9H492-2 | 13.173 | 13.690 | |
| Q9HC57 | 14.207 | 13.930 | |
| Q9NPH3;Q9NPH3-2;Q9NPH3-5 | 14.962 | 15.057 | |
| Q9UGM5;Q9UGM5-2 | 16.871 | 16.444 |
12600 rows × 2 columns
save missing values predictions
Sample ID protein groups
Sample_000 A0A075B6J9 15.300
A0A075B6Q5 16.434
A0A075B6R2 16.659
A0A075B6S5 16.318
A0A087WSY4 17.358
...
Sample_209 Q9P1W8;Q9P1W8-2;Q9P1W8-4 15.872
Q9UI40;Q9UI40-2 16.695
Q9UIW2 16.745
Q9UMX0;Q9UMX0-2;Q9UMX0-4 13.335
Q9UP79 15.987
Name: intensity, Length: 46401, dtype: float32
Plots#
validation data
| latent dimension 1 | latent dimension 2 | latent dimension 3 | latent dimension 4 | latent dimension 5 | latent dimension 6 | latent dimension 7 | latent dimension 8 | latent dimension 9 | latent dimension 10 | |
|---|---|---|---|---|---|---|---|---|---|---|
| Sample ID | ||||||||||
| Sample_000 | -0.825 | 1.274 | -1.104 | 7.398 | -3.532 | -0.142 | -0.217 | 5.788 | 1.560 | -1.882 |
| Sample_001 | -0.190 | 0.541 | -2.300 | 4.448 | -0.669 | -0.372 | 1.749 | 4.905 | -0.120 | -0.185 |
| Sample_002 | 1.380 | 5.778 | -0.068 | 3.423 | -2.616 | -3.149 | 2.774 | 3.796 | -2.986 | -0.592 |
| Sample_003 | 0.730 | 0.779 | -0.208 | 7.176 | -5.805 | -1.042 | 2.022 | 4.327 | -0.557 | -2.079 |
| Sample_004 | 1.333 | 1.295 | -3.153 | 4.255 | -5.602 | -1.690 | 1.478 | 5.385 | 3.131 | -0.963 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| Sample_205 | -2.632 | 4.839 | -1.318 | 2.730 | -1.926 | -4.093 | 2.155 | -1.988 | -0.551 | -4.772 |
| Sample_206 | -1.581 | 3.170 | -5.087 | 3.600 | 1.783 | 0.827 | -3.293 | -2.946 | 0.791 | -1.887 |
| Sample_207 | -3.670 | 2.081 | -2.094 | 1.203 | -1.005 | 0.897 | 0.806 | 0.178 | 4.306 | -3.981 |
| Sample_208 | -3.172 | 1.255 | -3.905 | -0.930 | 0.230 | 0.162 | 1.268 | -0.410 | -2.571 | -2.825 |
| Sample_209 | -1.497 | 0.069 | -3.491 | 2.529 | -4.749 | 2.446 | 2.462 | -2.196 | -2.417 | 0.657 |
210 rows × 10 columns
Comparisons#
Simulated NAs : Artificially created NAs. Some data was sampled and set explicitly to misssing before it was fed to the model for reconstruction.
Validation data#
all measured (identified, observed) peptides in validation data
The simulated NA for the validation step are real test data (not used for training nor early stopping)
Selected as truth to compare to: observed
{'DAE': {'MSE': 0.4580116766645174,
'MAE': 0.43230934764953793,
'N': 12600,
'prop': 1.0}}
Test Datasplit#
Selected as truth to compare to: observed
{'DAE': {'MSE': 0.4780007251571154,
'MAE': 0.436044456563813,
'N': 12600,
'prop': 1.0}}
Save all metrics as json
{ 'test_simulated_na': { 'DAE': { 'MAE': 0.436044456563813,
'MSE': 0.4780007251571154,
'N': 12600,
'prop': 1.0}},
'valid_simulated_na': { 'DAE': { 'MAE': 0.43230934764953793,
'MSE': 0.4580116766645174,
'N': 12600,
'prop': 1.0}}}
| subset | valid_simulated_na | test_simulated_na | |
|---|---|---|---|
| model | metric_name | ||
| DAE | MSE | 0.458 | 0.478 |
| MAE | 0.432 | 0.436 | |
| N | 12,600.000 | 12,600.000 | |
| prop | 1.000 | 1.000 |
Save predictions#
Config#
{}
{'M': 1421,
'batch_size': 64,
'cuda': False,
'data': Path('runs/alzheimer_study/data'),
'epoch_trained': 156,
'epochs_max': 300,
'file_format': 'csv',
'fn_rawfile_metadata': 'https://raw.githubusercontent.com/RasmussenLab/njab/HEAD/docs/tutorial/data/alzheimer/meta.csv',
'folder_data': '',
'folder_experiment': Path('runs/alzheimer_study'),
'hidden_layers': [64],
'latent_dim': 10,
'meta_cat_col': None,
'meta_date_col': None,
'model': 'DAE',
'model_key': 'DAE',
'n_params': 184983,
'out_figures': Path('runs/alzheimer_study/figures'),
'out_folder': Path('runs/alzheimer_study'),
'out_metrics': Path('runs/alzheimer_study'),
'out_models': Path('runs/alzheimer_study'),
'out_preds': Path('runs/alzheimer_study/preds'),
'patience': 25,
'sample_idx_position': 0,
'save_pred_real_na': True}