Fit logistic regression model#
based on different imputation methods
baseline: reference
model: any other selected imputation method
Parameters#
Default and set parameters for the notebook.
folder_data: str = '' # specify data directory if needed
fn_clinical_data = "data/ALD_study/processed/ald_metadata_cli.csv"
folder_experiment = "runs/appl_ald_data/plasma/proteinGroups"
model_key = 'VAE'
target = 'kleiner'
sample_id_col = 'Sample ID'
cutoff_target: int = 2 # => for binarization target >= cutoff_target
file_format = "csv"
out_folder = 'diff_analysis'
fn_qc_samples = '' # 'data/ALD_study/processed/qc_plasma_proteinGroups.pkl'
baseline = 'RSN' # default is RSN, as this was used in the original ALD Niu. et. al 2022
template_pred = 'pred_real_na_{}.csv' # fixed, do not change
# Parameters
cutoff_target = 0.5
folder_experiment = "runs/alzheimer_study"
target = "AD"
baseline = "PI"
model_key = "DAE"
out_folder = "diff_analysis"
fn_clinical_data = "runs/alzheimer_study/data/clinical_data.csv"
root - INFO Removed from global namespace: folder_data
root - INFO Removed from global namespace: fn_clinical_data
root - INFO Removed from global namespace: folder_experiment
root - INFO Removed from global namespace: model_key
root - INFO Removed from global namespace: target
root - INFO Removed from global namespace: sample_id_col
root - INFO Removed from global namespace: cutoff_target
root - INFO Removed from global namespace: file_format
root - INFO Removed from global namespace: out_folder
root - INFO Removed from global namespace: fn_qc_samples
root - INFO Removed from global namespace: baseline
root - INFO Removed from global namespace: template_pred
root - INFO Already set attribute: folder_experiment has value runs/alzheimer_study
root - INFO Already set attribute: out_folder has value diff_analysis
{'baseline': 'PI',
'cutoff_target': 0.5,
'data': PosixPath('runs/alzheimer_study/data'),
'file_format': 'csv',
'fn_clinical_data': 'runs/alzheimer_study/data/clinical_data.csv',
'fn_qc_samples': '',
'folder_data': '',
'folder_experiment': PosixPath('runs/alzheimer_study'),
'model_key': 'DAE',
'out_figures': PosixPath('runs/alzheimer_study/figures'),
'out_folder': PosixPath('runs/alzheimer_study/diff_analysis/AD/PI_vs_DAE'),
'out_metrics': PosixPath('runs/alzheimer_study'),
'out_models': PosixPath('runs/alzheimer_study'),
'out_preds': PosixPath('runs/alzheimer_study/preds'),
'sample_id_col': 'Sample ID',
'target': 'AD',
'template_pred': 'pred_real_na_{}.csv'}
Load data#
Load target#
target = pd.read_csv(args.fn_clinical_data,
index_col=0,
usecols=[args.sample_id_col, args.target])
target = target.dropna()
target
| AD | |
|---|---|
| Sample ID | |
| Sample_000 | 0 |
| Sample_001 | 1 |
| Sample_002 | 1 |
| Sample_003 | 1 |
| Sample_004 | 1 |
| ... | ... |
| Sample_205 | 1 |
| Sample_206 | 0 |
| Sample_207 | 0 |
| Sample_208 | 0 |
| Sample_209 | 0 |
210 rows × 1 columns
MS proteomics or specified omics data#
Aggregated from data splits of the imputation workflow run before.
pimmslearn.io.datasplits - INFO Loaded 'train_X' from file: runs/alzheimer_study/data/train_X.csv
pimmslearn.io.datasplits - INFO Loaded 'val_y' from file: runs/alzheimer_study/data/val_y.csv
pimmslearn.io.datasplits - INFO Loaded 'test_y' from file: runs/alzheimer_study/data/test_y.csv
Sample ID protein groups
Sample_160 Q9NSC7 15.302
Sample_148 Q9P1W8;Q9P1W8-2;Q9P1W8-4 15.412
Sample_106 A0A0A0MTI5;B8ZWD1;P07108;P07108-2;P07108-3;P07108-4;P07108-5 18.073
Sample_022 J9JIG6;Q96EG1 13.759
Sample_118 Q13554;Q13554-2;Q13554-3;Q13554-4;Q13554-5;Q13554-7;Q13554-8 16.466
Name: intensity, dtype: float64
Get overlap between independent features and target
Select by ALD criteria#
Use parameters as specified in ALD study.
root - INFO Initally: N samples: 210, M feat: 1421
root - INFO Dropped features quantified in less than 126 samples.
root - INFO After feat selection: N samples: 210, M feat: 1213
root - INFO Min No. of Protein-Groups in single sample: 754
root - INFO Finally: N samples: 210, M feat: 1213
| protein groups | A0A024QZX5;A0A087X1N8;P35237 | A0A024R0T9;K7ER74;P02655 | A0A024R3W6;A0A024R412;O60462;O60462-2;O60462-3;O60462-4;O60462-5;Q7LBX6;X5D2Q8 | A0A024R644;A0A0A0MRU5;A0A1B0GWI2;O75503 | A0A075B6H9 | A0A075B6I0 | A0A075B6I1 | A0A075B6I6 | A0A075B6I9 | A0A075B6J9 | ... | Q9Y653;Q9Y653-2;Q9Y653-3 | Q9Y696 | Q9Y6C2 | Q9Y6N6 | Q9Y6N7;Q9Y6N7-2;Q9Y6N7-4 | Q9Y6R7 | Q9Y6X5 | Q9Y6Y8;Q9Y6Y8-2 | Q9Y6Y9 | S4R3U6 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sample ID | |||||||||||||||||||||
| Sample_000 | 15.912 | 16.852 | 15.570 | 16.481 | 20.246 | 16.764 | 17.584 | 16.988 | 20.054 | NaN | ... | 16.012 | 15.178 | NaN | 15.050 | 16.842 | 19.863 | NaN | 19.563 | 12.837 | 12.805 |
| Sample_001 | 15.936 | 16.874 | 15.519 | 16.387 | 19.941 | 18.786 | 17.144 | NaN | 19.067 | 16.188 | ... | 15.528 | 15.576 | NaN | 14.833 | 16.597 | 20.299 | 15.556 | 19.386 | 13.970 | 12.442 |
| Sample_002 | 16.111 | 14.523 | 15.935 | 16.416 | 19.251 | 16.832 | 15.671 | 17.012 | 18.569 | NaN | ... | 15.229 | 14.728 | 13.757 | 15.118 | 17.440 | 19.598 | 15.735 | 20.447 | 12.636 | 12.505 |
| Sample_003 | 16.107 | 17.032 | 15.802 | 16.979 | 19.628 | 17.852 | 18.877 | 14.182 | 18.985 | 13.438 | ... | 15.495 | 14.590 | 14.682 | 15.140 | 17.356 | 19.429 | NaN | 20.216 | 12.627 | 12.445 |
| Sample_004 | 15.603 | 15.331 | 15.375 | 16.679 | 20.450 | 18.682 | 17.081 | 14.140 | 19.686 | 14.495 | ... | 14.757 | 15.094 | 14.048 | 15.256 | 17.075 | 19.582 | 15.328 | 19.867 | 13.145 | 12.235 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| Sample_205 | 15.682 | 16.886 | 14.910 | 16.482 | 17.705 | 17.039 | NaN | 16.413 | 19.102 | 16.064 | ... | 15.235 | 15.684 | 14.236 | 15.415 | 17.551 | 17.922 | 16.340 | 19.928 | 12.929 | 11.802 |
| Sample_206 | 15.798 | 17.554 | 15.600 | 15.938 | 18.154 | 18.152 | 16.503 | 16.860 | 18.538 | 15.288 | ... | 15.422 | 16.106 | NaN | 15.345 | 17.084 | 18.708 | 14.249 | 19.433 | NaN | NaN |
| Sample_207 | 15.739 | 16.877 | 15.469 | 16.898 | 18.636 | 17.950 | 16.321 | 16.401 | 18.849 | 17.580 | ... | 15.808 | 16.098 | 14.403 | 15.715 | 16.586 | 18.725 | 16.138 | 19.599 | 13.637 | 11.174 |
| Sample_208 | 15.477 | 16.779 | 14.995 | 16.132 | 14.908 | 17.530 | NaN | 16.119 | 18.368 | 15.202 | ... | 15.157 | 16.712 | NaN | 14.640 | 16.533 | 19.411 | 15.807 | 19.545 | 13.216 | NaN |
| Sample_209 | 15.727 | 17.261 | 15.175 | 16.235 | 17.893 | 17.744 | 16.371 | 15.780 | 18.806 | 16.532 | ... | 15.237 | 15.652 | 15.211 | 14.205 | 16.749 | 19.275 | 15.732 | 19.577 | 11.042 | 11.791 |
210 rows × 1213 columns
Number of complete cases which can be used:
Samples available both in proteomics data and for target: 210
Load imputations from specified model#
missing values pred. by DAE: runs/alzheimer_study/preds/pred_real_na_DAE.csv
Sample ID protein groups
Sample_171 O15197;O15197-3 15.074
Sample_009 Q9BUN1 16.987
Sample_195 E7EWD3;O75077;O75077-2;O75077-3 15.668
Name: intensity, dtype: float64
Load imputations from baseline model#
Sample ID protein groups
Sample_000 A0A075B6J9 13.233
A0A075B6Q5 14.650
A0A075B6R2 12.676
A0A075B6S5 13.685
A0A087WSY4 11.567
...
Sample_209 Q9P1W8;Q9P1W8-2;Q9P1W8-4 12.558
Q9UI40;Q9UI40-2 13.031
Q9UIW2 12.614
Q9UMX0;Q9UMX0-2;Q9UMX0-4 13.098
Q9UP79 12.307
Name: intensity, Length: 46401, dtype: float64
Modeling setup#
General approach:
use one train, test split of the data
select best 10 features from training data
X_train,y_trainbefore binarization of targetdichotomize (binarize) data into to groups (zero and 1)
evaluate model on the test data
X_test,y_test
Repeat general approach for
all original ald data: all features justed in original ALD study
all model data: all features available my using the self supervised deep learning model
newly available feat only: the subset of features available from the self supervised deep learning model which were newly retained using the new approach
All data:
| protein groups | A0A024QZX5;A0A087X1N8;P35237 | A0A024R0T9;K7ER74;P02655 | A0A024R3W6;A0A024R412;O60462;O60462-2;O60462-3;O60462-4;O60462-5;Q7LBX6;X5D2Q8 | A0A024R644;A0A0A0MRU5;A0A1B0GWI2;O75503 | A0A075B6H7 | A0A075B6H9 | A0A075B6I0 | A0A075B6I1 | A0A075B6I6 | A0A075B6I9 | ... | Q9Y653;Q9Y653-2;Q9Y653-3 | Q9Y696 | Q9Y6C2 | Q9Y6N6 | Q9Y6N7;Q9Y6N7-2;Q9Y6N7-4 | Q9Y6R7 | Q9Y6X5 | Q9Y6Y8;Q9Y6Y8-2 | Q9Y6Y9 | S4R3U6 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sample ID | |||||||||||||||||||||
| Sample_000 | 15.912 | 16.852 | 15.570 | 16.481 | 17.301 | 20.246 | 16.764 | 17.584 | 16.988 | 20.054 | ... | 16.012 | 15.178 | 13.777 | 15.050 | 16.842 | 19.863 | 16.128 | 19.563 | 12.837 | 12.805 |
| Sample_001 | 15.936 | 16.874 | 15.519 | 16.387 | 13.796 | 19.941 | 18.786 | 17.144 | 16.926 | 19.067 | ... | 15.528 | 15.576 | 13.832 | 14.833 | 16.597 | 20.299 | 15.556 | 19.386 | 13.970 | 12.442 |
| Sample_002 | 16.111 | 14.523 | 15.935 | 16.416 | 18.175 | 19.251 | 16.832 | 15.671 | 17.012 | 18.569 | ... | 15.229 | 14.728 | 13.757 | 15.118 | 17.440 | 19.598 | 15.735 | 20.447 | 12.636 | 12.505 |
| Sample_003 | 16.107 | 17.032 | 15.802 | 16.979 | 15.963 | 19.628 | 17.852 | 18.877 | 14.182 | 18.985 | ... | 15.495 | 14.590 | 14.682 | 15.140 | 17.356 | 19.429 | 15.941 | 20.216 | 12.627 | 12.445 |
| Sample_004 | 15.603 | 15.331 | 15.375 | 16.679 | 15.473 | 20.450 | 18.682 | 17.081 | 14.140 | 19.686 | ... | 14.757 | 15.094 | 14.048 | 15.256 | 17.075 | 19.582 | 15.328 | 19.867 | 13.145 | 12.235 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| Sample_205 | 15.682 | 16.886 | 14.910 | 16.482 | 15.195 | 17.705 | 17.039 | 15.875 | 16.413 | 19.102 | ... | 15.235 | 15.684 | 14.236 | 15.415 | 17.551 | 17.922 | 16.340 | 19.928 | 12.929 | 11.802 |
| Sample_206 | 15.798 | 17.554 | 15.600 | 15.938 | 15.172 | 18.154 | 18.152 | 16.503 | 16.860 | 18.538 | ... | 15.422 | 16.106 | 14.681 | 15.345 | 17.084 | 18.708 | 14.249 | 19.433 | 12.120 | 11.030 |
| Sample_207 | 15.739 | 16.877 | 15.469 | 16.898 | 13.161 | 18.636 | 17.950 | 16.321 | 16.401 | 18.849 | ... | 15.808 | 16.098 | 14.403 | 15.715 | 16.586 | 18.725 | 16.138 | 19.599 | 13.637 | 11.174 |
| Sample_208 | 15.477 | 16.779 | 14.995 | 16.132 | 13.825 | 14.908 | 17.530 | 16.727 | 16.119 | 18.368 | ... | 15.157 | 16.712 | 14.391 | 14.640 | 16.533 | 19.411 | 15.807 | 19.545 | 13.216 | 10.860 |
| Sample_209 | 15.727 | 17.261 | 15.175 | 16.235 | 14.597 | 17.893 | 17.744 | 16.371 | 15.780 | 18.806 | ... | 15.237 | 15.652 | 15.211 | 14.205 | 16.749 | 19.275 | 15.732 | 19.577 | 11.042 | 11.791 |
210 rows × 1421 columns
Subset of data by ALD criteria#
| protein groups | A0A024QZX5;A0A087X1N8;P35237 | A0A024R0T9;K7ER74;P02655 | A0A024R3W6;A0A024R412;O60462;O60462-2;O60462-3;O60462-4;O60462-5;Q7LBX6;X5D2Q8 | A0A024R644;A0A0A0MRU5;A0A1B0GWI2;O75503 | A0A075B6H9 | A0A075B6I0 | A0A075B6I1 | A0A075B6I6 | A0A075B6I9 | A0A075B6K4 | ... | O14793 | O95479;R4GMU1 | P01282;P01282-2 | P10619;P10619-2;X6R5C5;X6R8A1 | P21810 | Q14956;Q14956-2 | Q6ZMP0;Q6ZMP0-2 | Q9HBW1 | Q9NY15 | P17050 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sample ID | |||||||||||||||||||||
| Sample_000 | 15.912 | 16.852 | 15.570 | 16.481 | 20.246 | 16.764 | 17.584 | 16.988 | 20.054 | 16.148 | ... | 13.148 | 12.613 | 13.129 | 12.601 | 13.761 | 12.267 | 12.442 | 13.088 | 13.974 | 12.066 |
| Sample_001 | 15.936 | 16.874 | 15.519 | 16.387 | 19.941 | 18.786 | 17.144 | 11.221 | 19.067 | 16.127 | ... | 11.923 | 13.430 | 12.714 | 12.538 | 11.670 | 12.748 | 14.913 | 13.002 | 12.529 | 11.871 |
| Sample_002 | 16.111 | 14.523 | 15.935 | 16.416 | 19.251 | 16.832 | 15.671 | 17.012 | 18.569 | 15.387 | ... | 12.855 | 12.808 | 12.988 | 12.258 | 14.324 | 12.307 | 13.316 | 12.469 | 12.247 | 12.723 |
| Sample_003 | 16.107 | 17.032 | 15.802 | 16.979 | 19.628 | 17.852 | 18.877 | 14.182 | 18.985 | 16.565 | ... | 14.185 | 12.732 | 12.625 | 12.677 | 14.167 | 13.267 | 12.173 | 13.430 | 12.890 | 12.953 |
| Sample_004 | 15.603 | 15.331 | 15.375 | 16.679 | 20.450 | 18.682 | 17.081 | 14.140 | 19.686 | 16.418 | ... | 11.178 | 12.671 | 13.967 | 12.890 | 13.532 | 11.879 | 12.613 | 13.227 | 12.763 | 11.625 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| Sample_205 | 15.682 | 16.886 | 14.910 | 16.482 | 17.705 | 17.039 | 12.721 | 16.413 | 19.102 | 15.350 | ... | 14.269 | 14.064 | 16.826 | 18.182 | 15.225 | 15.044 | 14.192 | 16.605 | 14.995 | 14.257 |
| Sample_206 | 15.798 | 17.554 | 15.600 | 15.938 | 18.154 | 18.152 | 16.503 | 16.860 | 18.538 | 16.582 | ... | 14.273 | 17.700 | 16.802 | 20.202 | 15.280 | 15.086 | 13.978 | 18.086 | 15.557 | 14.171 |
| Sample_207 | 15.739 | 16.877 | 15.469 | 16.898 | 18.636 | 17.950 | 16.321 | 16.401 | 18.849 | 15.768 | ... | 14.473 | 16.882 | 16.917 | 20.105 | 15.690 | 15.135 | 13.138 | 17.066 | 15.706 | 15.690 |
| Sample_208 | 15.477 | 16.779 | 14.995 | 16.132 | 14.908 | 17.530 | 13.070 | 16.119 | 18.368 | 17.560 | ... | 15.234 | 17.175 | 16.521 | 18.859 | 15.305 | 15.161 | 13.006 | 17.917 | 15.396 | 14.371 |
| Sample_209 | 15.727 | 17.261 | 15.175 | 16.235 | 17.893 | 17.744 | 16.371 | 15.780 | 18.806 | 16.338 | ... | 14.556 | 16.656 | 16.954 | 18.493 | 15.823 | 14.626 | 13.385 | 17.767 | 15.687 | 13.573 |
210 rows × 1213 columns
Features which would not have been included using ALD criteria:
Index(['A0A075B6H7', 'A0A075B6Q5', 'A0A075B7B8', 'A0A087WSY4',
'A0A087WTT8;A0A0A0MQX5;O94779;O94779-2', 'A0A087WXB8;Q9Y274',
'A0A087WXE9;E9PQ70;Q6UXH9;Q6UXH9-2;Q6UXH9-3',
'A0A087X1Z2;C9JTV4;H0Y4Y4;Q8WYH2;Q96C19;Q9BUP0;Q9BUP0-2',
'A0A0A0MQS9;A0A0A0MTC7;Q16363;Q16363-2', 'A0A0A0MSN4;P12821;P12821-2',
...
'Q9NZ94;Q9NZ94-2;Q9NZ94-3', 'Q9NZU1', 'Q9P1W8;Q9P1W8-2;Q9P1W8-4',
'Q9UHI8', 'Q9UI40;Q9UI40-2',
'Q9UIB8;Q9UIB8-2;Q9UIB8-3;Q9UIB8-4;Q9UIB8-5;Q9UIB8-6',
'Q9UKZ4;Q9UKZ4-2', 'Q9UMX0;Q9UMX0-2;Q9UMX0-4', 'Q9Y281;Q9Y281-3',
'Q9Y490'],
dtype='object', name='protein groups', length=208)
Binarize targets, but also keep groups for stratification
| AD | 0 | 1 |
|---|---|---|
| AD | ||
| False | 122 | 0 |
| True | 0 | 88 |
Determine best number of parameters by cross validation procedure#
using subset of data by ALD criteria:
0%| | 0/1 [00:00<?, ?it/s]
100%|██████████| 1/1 [00:00<00:00, 100.29it/s]
0%| | 0/2 [00:00<?, ?it/s]
100%|██████████| 2/2 [00:00<00:00, 3.98it/s]
100%|██████████| 2/2 [00:00<00:00, 3.97it/s]
0%| | 0/3 [00:00<?, ?it/s]
67%|██████▋ | 2/3 [00:00<00:00, 6.47it/s]
100%|██████████| 3/3 [00:00<00:00, 4.85it/s]
100%|██████████| 3/3 [00:00<00:00, 5.09it/s]
0%| | 0/4 [00:00<?, ?it/s]
50%|█████ | 2/4 [00:00<00:00, 6.56it/s]
75%|███████▌ | 3/4 [00:00<00:00, 4.21it/s]
100%|██████████| 4/4 [00:01<00:00, 3.55it/s]
100%|██████████| 4/4 [00:01<00:00, 3.92it/s]
0%| | 0/5 [00:00<?, ?it/s]
40%|████ | 2/5 [00:00<00:00, 7.01it/s]
60%|██████ | 3/5 [00:00<00:00, 5.12it/s]
80%|████████ | 4/5 [00:00<00:00, 4.79it/s]
100%|██████████| 5/5 [00:01<00:00, 4.66it/s]
100%|██████████| 5/5 [00:01<00:00, 4.94it/s]
0%| | 0/6 [00:00<?, ?it/s]
33%|███▎ | 2/6 [00:00<00:01, 3.51it/s]
50%|█████ | 3/6 [00:01<00:01, 2.79it/s]
67%|██████▋ | 4/6 [00:01<00:00, 2.50it/s]
83%|████████▎ | 5/6 [00:02<00:00, 2.26it/s]
100%|██████████| 6/6 [00:02<00:00, 2.42it/s]
100%|██████████| 6/6 [00:02<00:00, 2.52it/s]
0%| | 0/7 [00:00<?, ?it/s]
29%|██▊ | 2/7 [00:00<00:01, 4.23it/s]
43%|████▎ | 3/7 [00:00<00:01, 3.28it/s]
57%|█████▋ | 4/7 [00:01<00:00, 3.15it/s]
71%|███████▏ | 5/7 [00:01<00:00, 3.02it/s]
86%|████████▌ | 6/7 [00:02<00:00, 2.60it/s]
100%|██████████| 7/7 [00:02<00:00, 2.36it/s]
100%|██████████| 7/7 [00:02<00:00, 2.72it/s]
0%| | 0/8 [00:00<?, ?it/s]
25%|██▌ | 2/8 [00:00<00:00, 7.92it/s]
38%|███▊ | 3/8 [00:00<00:00, 5.14it/s]
50%|█████ | 4/8 [00:00<00:00, 4.91it/s]
62%|██████▎ | 5/8 [00:00<00:00, 4.64it/s]
75%|███████▌ | 6/8 [00:01<00:00, 4.54it/s]
88%|████████▊ | 7/8 [00:01<00:00, 4.44it/s]
100%|██████████| 8/8 [00:01<00:00, 4.31it/s]
100%|██████████| 8/8 [00:01<00:00, 4.67it/s]
0%| | 0/9 [00:00<?, ?it/s]
22%|██▏ | 2/9 [00:00<00:00, 8.56it/s]
33%|███▎ | 3/9 [00:00<00:00, 6.02it/s]
44%|████▍ | 4/9 [00:00<00:01, 4.70it/s]
56%|█████▌ | 5/9 [00:01<00:00, 4.30it/s]
67%|██████▋ | 6/9 [00:01<00:00, 4.43it/s]
78%|███████▊ | 7/9 [00:01<00:00, 4.45it/s]
89%|████████▉ | 8/9 [00:01<00:00, 4.45it/s]
100%|██████████| 9/9 [00:01<00:00, 4.49it/s]
100%|██████████| 9/9 [00:01<00:00, 4.72it/s]
0%| | 0/10 [00:00<?, ?it/s]
20%|██ | 2/10 [00:00<00:00, 9.85it/s]
30%|███ | 3/10 [00:00<00:01, 6.39it/s]
40%|████ | 4/10 [00:00<00:01, 5.02it/s]
50%|█████ | 5/10 [00:00<00:01, 4.58it/s]
60%|██████ | 6/10 [00:01<00:00, 4.53it/s]
70%|███████ | 7/10 [00:01<00:00, 4.44it/s]
80%|████████ | 8/10 [00:01<00:00, 4.40it/s]
90%|█████████ | 9/10 [00:01<00:00, 4.42it/s]
100%|██████████| 10/10 [00:02<00:00, 4.03it/s]
100%|██████████| 10/10 [00:02<00:00, 4.59it/s]
0%| | 0/11 [00:00<?, ?it/s]
18%|█▊ | 2/11 [00:00<00:01, 8.32it/s]
27%|██▋ | 3/11 [00:00<00:01, 4.52it/s]
36%|███▋ | 4/11 [00:00<00:01, 4.43it/s]
45%|████▌ | 5/11 [00:01<00:01, 4.26it/s]
55%|█████▍ | 6/11 [00:01<00:01, 4.19it/s]
64%|██████▎ | 7/11 [00:01<00:00, 4.31it/s]
73%|███████▎ | 8/11 [00:01<00:00, 4.14it/s]
82%|████████▏ | 9/11 [00:02<00:00, 4.08it/s]
91%|█████████ | 10/11 [00:02<00:00, 4.16it/s]
100%|██████████| 11/11 [00:02<00:00, 4.22it/s]
100%|██████████| 11/11 [00:02<00:00, 4.35it/s]
0%| | 0/12 [00:00<?, ?it/s]
17%|█▋ | 2/12 [00:00<00:00, 10.28it/s]
33%|███▎ | 4/12 [00:00<00:01, 4.94it/s]
42%|████▏ | 5/12 [00:00<00:01, 4.73it/s]
50%|█████ | 6/12 [00:01<00:01, 4.64it/s]
58%|█████▊ | 7/12 [00:01<00:01, 4.36it/s]
67%|██████▋ | 8/12 [00:01<00:00, 4.26it/s]
75%|███████▌ | 9/12 [00:01<00:00, 4.13it/s]
83%|████████▎ | 10/12 [00:02<00:00, 4.13it/s]
92%|█████████▏| 11/12 [00:02<00:00, 3.88it/s]
100%|██████████| 12/12 [00:02<00:00, 3.81it/s]
100%|██████████| 12/12 [00:02<00:00, 4.31it/s]
0%| | 0/13 [00:00<?, ?it/s]
15%|█▌ | 2/13 [00:00<00:01, 6.32it/s]
23%|██▎ | 3/13 [00:00<00:01, 5.02it/s]
31%|███ | 4/13 [00:00<00:01, 4.74it/s]
38%|███▊ | 5/13 [00:01<00:01, 4.35it/s]
46%|████▌ | 6/13 [00:01<00:01, 4.45it/s]
54%|█████▍ | 7/13 [00:01<00:01, 4.41it/s]
62%|██████▏ | 8/13 [00:01<00:01, 4.36it/s]
69%|██████▉ | 9/13 [00:02<00:00, 4.20it/s]
77%|███████▋ | 10/13 [00:02<00:00, 4.15it/s]
85%|████████▍ | 11/13 [00:02<00:00, 4.18it/s]
92%|█████████▏| 12/13 [00:02<00:00, 4.11it/s]
100%|██████████| 13/13 [00:02<00:00, 4.23it/s]
100%|██████████| 13/13 [00:02<00:00, 4.39it/s]
0%| | 0/14 [00:00<?, ?it/s]
14%|█▍ | 2/14 [00:00<00:01, 6.81it/s]
21%|██▏ | 3/14 [00:00<00:02, 4.72it/s]
29%|██▊ | 4/14 [00:00<00:02, 3.92it/s]
36%|███▌ | 5/14 [00:01<00:02, 3.84it/s]
43%|████▎ | 6/14 [00:01<00:02, 3.74it/s]
50%|█████ | 7/14 [00:01<00:01, 3.65it/s]
57%|█████▋ | 8/14 [00:02<00:01, 3.68it/s]
64%|██████▍ | 9/14 [00:02<00:01, 3.63it/s]
71%|███████▏ | 10/14 [00:02<00:01, 3.76it/s]
79%|███████▊ | 11/14 [00:02<00:00, 3.91it/s]
86%|████████▌ | 12/14 [00:03<00:00, 3.95it/s]
93%|█████████▎| 13/14 [00:03<00:00, 3.96it/s]
100%|██████████| 14/14 [00:03<00:00, 3.95it/s]
100%|██████████| 14/14 [00:03<00:00, 3.95it/s]
0%| | 0/15 [00:00<?, ?it/s]
13%|█▎ | 2/15 [00:00<00:01, 7.09it/s]
20%|██ | 3/15 [00:00<00:02, 5.32it/s]
27%|██▋ | 4/15 [00:00<00:02, 4.47it/s]
33%|███▎ | 5/15 [00:01<00:02, 3.54it/s]
40%|████ | 6/15 [00:01<00:02, 3.56it/s]
47%|████▋ | 7/15 [00:01<00:02, 3.69it/s]
53%|█████▎ | 8/15 [00:01<00:01, 3.78it/s]
60%|██████ | 9/15 [00:02<00:01, 3.88it/s]
67%|██████▋ | 10/15 [00:02<00:01, 3.85it/s]
73%|███████▎ | 11/15 [00:02<00:01, 3.92it/s]
80%|████████ | 12/15 [00:02<00:00, 4.06it/s]
87%|████████▋ | 13/15 [00:03<00:00, 4.13it/s]
93%|█████████▎| 14/15 [00:03<00:00, 4.22it/s]
100%|██████████| 15/15 [00:03<00:00, 4.08it/s]
100%|██████████| 15/15 [00:03<00:00, 4.06it/s]
| fit_time | score_time | test_precision | test_recall | test_f1 | test_balanced_accuracy | test_roc_auc | test_average_precision | n_observations | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| mean | std | mean | std | mean | std | mean | std | mean | std | mean | std | mean | std | mean | std | mean | std | |
| n_features | ||||||||||||||||||
| 1 | 0.004 | 0.001 | 0.038 | 0.004 | 0.878 | 0.202 | 0.155 | 0.080 | 0.255 | 0.115 | 0.569 | 0.039 | 0.861 | 0.061 | 0.830 | 0.087 | 210.000 | 0.000 |
| 2 | 0.004 | 0.002 | 0.046 | 0.019 | 0.703 | 0.092 | 0.617 | 0.105 | 0.651 | 0.079 | 0.711 | 0.059 | 0.792 | 0.065 | 0.765 | 0.084 | 210.000 | 0.000 |
| 3 | 0.004 | 0.002 | 0.048 | 0.018 | 0.717 | 0.085 | 0.672 | 0.111 | 0.687 | 0.078 | 0.737 | 0.059 | 0.810 | 0.065 | 0.773 | 0.087 | 210.000 | 0.000 |
| 4 | 0.005 | 0.003 | 0.049 | 0.018 | 0.767 | 0.088 | 0.685 | 0.103 | 0.718 | 0.072 | 0.764 | 0.055 | 0.822 | 0.067 | 0.788 | 0.090 | 210.000 | 0.000 |
| 5 | 0.006 | 0.003 | 0.068 | 0.027 | 0.783 | 0.091 | 0.797 | 0.108 | 0.784 | 0.074 | 0.815 | 0.062 | 0.898 | 0.048 | 0.871 | 0.059 | 210.000 | 0.000 |
| 6 | 0.006 | 0.004 | 0.064 | 0.030 | 0.804 | 0.085 | 0.823 | 0.106 | 0.808 | 0.070 | 0.836 | 0.059 | 0.894 | 0.048 | 0.872 | 0.054 | 210.000 | 0.000 |
| 7 | 0.005 | 0.002 | 0.051 | 0.018 | 0.807 | 0.086 | 0.835 | 0.098 | 0.816 | 0.065 | 0.842 | 0.056 | 0.893 | 0.048 | 0.869 | 0.055 | 210.000 | 0.000 |
| 8 | 0.004 | 0.001 | 0.038 | 0.004 | 0.820 | 0.084 | 0.832 | 0.102 | 0.822 | 0.070 | 0.848 | 0.060 | 0.916 | 0.047 | 0.904 | 0.052 | 210.000 | 0.000 |
| 9 | 0.004 | 0.000 | 0.038 | 0.003 | 0.824 | 0.085 | 0.838 | 0.097 | 0.827 | 0.069 | 0.852 | 0.060 | 0.915 | 0.048 | 0.903 | 0.054 | 210.000 | 0.000 |
| 10 | 0.003 | 0.001 | 0.035 | 0.010 | 0.819 | 0.087 | 0.849 | 0.092 | 0.830 | 0.068 | 0.854 | 0.059 | 0.916 | 0.047 | 0.908 | 0.048 | 210.000 | 0.000 |
| 11 | 0.004 | 0.001 | 0.038 | 0.008 | 0.813 | 0.092 | 0.851 | 0.094 | 0.827 | 0.072 | 0.852 | 0.063 | 0.915 | 0.049 | 0.905 | 0.051 | 210.000 | 0.000 |
| 12 | 0.004 | 0.001 | 0.040 | 0.015 | 0.815 | 0.089 | 0.845 | 0.093 | 0.826 | 0.070 | 0.850 | 0.061 | 0.914 | 0.048 | 0.903 | 0.050 | 210.000 | 0.000 |
| 13 | 0.004 | 0.001 | 0.040 | 0.006 | 0.828 | 0.086 | 0.815 | 0.091 | 0.817 | 0.067 | 0.844 | 0.057 | 0.917 | 0.046 | 0.910 | 0.046 | 210.000 | 0.000 |
| 14 | 0.004 | 0.002 | 0.040 | 0.009 | 0.832 | 0.079 | 0.824 | 0.088 | 0.824 | 0.063 | 0.850 | 0.053 | 0.919 | 0.047 | 0.911 | 0.048 | 210.000 | 0.000 |
| 15 | 0.004 | 0.001 | 0.043 | 0.013 | 0.830 | 0.075 | 0.824 | 0.094 | 0.823 | 0.064 | 0.850 | 0.054 | 0.918 | 0.047 | 0.909 | 0.047 | 210.000 | 0.000 |
Using all data:
0%| | 0/1 [00:00<?, ?it/s]
100%|██████████| 1/1 [00:00<00:00, 442.53it/s]
0%| | 0/2 [00:00<?, ?it/s]
100%|██████████| 2/2 [00:00<00:00, 6.36it/s]
100%|██████████| 2/2 [00:00<00:00, 6.32it/s]
0%| | 0/3 [00:00<?, ?it/s]
67%|██████▋ | 2/3 [00:00<00:00, 6.90it/s]
100%|██████████| 3/3 [00:00<00:00, 4.54it/s]
100%|██████████| 3/3 [00:00<00:00, 4.84it/s]
0%| | 0/4 [00:00<?, ?it/s]
50%|█████ | 2/4 [00:00<00:00, 6.47it/s]
75%|███████▌ | 3/4 [00:00<00:00, 4.59it/s]
100%|██████████| 4/4 [00:00<00:00, 4.36it/s]
100%|██████████| 4/4 [00:00<00:00, 4.63it/s]
0%| | 0/5 [00:00<?, ?it/s]
40%|████ | 2/5 [00:00<00:00, 8.17it/s]
60%|██████ | 3/5 [00:00<00:00, 5.68it/s]
80%|████████ | 4/5 [00:00<00:00, 4.91it/s]
100%|██████████| 5/5 [00:00<00:00, 4.78it/s]
100%|██████████| 5/5 [00:00<00:00, 5.17it/s]
0%| | 0/6 [00:00<?, ?it/s]
33%|███▎ | 2/6 [00:00<00:00, 7.55it/s]
50%|█████ | 3/6 [00:00<00:00, 4.83it/s]
67%|██████▋ | 4/6 [00:00<00:00, 4.07it/s]
83%|████████▎ | 5/6 [00:01<00:00, 3.74it/s]
100%|██████████| 6/6 [00:01<00:00, 3.68it/s]
100%|██████████| 6/6 [00:01<00:00, 4.06it/s]
0%| | 0/7 [00:00<?, ?it/s]
29%|██▊ | 2/7 [00:00<00:00, 6.72it/s]
43%|████▎ | 3/7 [00:00<00:00, 4.60it/s]
57%|█████▋ | 4/7 [00:00<00:00, 4.16it/s]
71%|███████▏ | 5/7 [00:01<00:00, 3.80it/s]
86%|████████▌ | 6/7 [00:01<00:00, 3.60it/s]
100%|██████████| 7/7 [00:01<00:00, 3.63it/s]
100%|██████████| 7/7 [00:01<00:00, 3.95it/s]
0%| | 0/8 [00:00<?, ?it/s]
25%|██▌ | 2/8 [00:00<00:00, 6.20it/s]
38%|███▊ | 3/8 [00:00<00:00, 6.28it/s]
50%|█████ | 4/8 [00:00<00:00, 4.89it/s]
62%|██████▎ | 5/8 [00:01<00:00, 4.34it/s]
75%|███████▌ | 6/8 [00:01<00:00, 4.18it/s]
88%|████████▊ | 7/8 [00:01<00:00, 4.10it/s]
100%|██████████| 8/8 [00:01<00:00, 3.97it/s]
100%|██████████| 8/8 [00:01<00:00, 4.39it/s]
0%| | 0/9 [00:00<?, ?it/s]
22%|██▏ | 2/9 [00:00<00:01, 6.65it/s]
33%|███▎ | 3/9 [00:00<00:01, 5.24it/s]
44%|████▍ | 4/9 [00:00<00:01, 3.85it/s]
56%|█████▌ | 5/9 [00:01<00:01, 2.90it/s]
67%|██████▋ | 6/9 [00:01<00:01, 2.83it/s]
78%|███████▊ | 7/9 [00:02<00:00, 2.62it/s]
89%|████████▉ | 8/9 [00:02<00:00, 2.54it/s]
100%|██████████| 9/9 [00:03<00:00, 2.53it/s]
100%|██████████| 9/9 [00:03<00:00, 2.94it/s]
0%| | 0/10 [00:00<?, ?it/s]
20%|██ | 2/10 [00:00<00:01, 4.06it/s]
30%|███ | 3/10 [00:00<00:02, 2.99it/s]
40%|████ | 4/10 [00:01<00:02, 2.66it/s]
50%|█████ | 5/10 [00:01<00:01, 2.52it/s]
60%|██████ | 6/10 [00:02<00:01, 2.38it/s]
70%|███████ | 7/10 [00:02<00:01, 2.13it/s]
80%|████████ | 8/10 [00:03<00:01, 1.97it/s]
90%|█████████ | 9/10 [00:04<00:00, 1.90it/s]
100%|██████████| 10/10 [00:04<00:00, 1.90it/s]
100%|██████████| 10/10 [00:04<00:00, 2.19it/s]
0%| | 0/11 [00:00<?, ?it/s]
18%|█▊ | 2/11 [00:00<00:02, 4.06it/s]
27%|██▋ | 3/11 [00:00<00:02, 2.84it/s]
36%|███▋ | 4/11 [00:01<00:02, 2.96it/s]
45%|████▌ | 5/11 [00:01<00:02, 2.97it/s]
55%|█████▍ | 6/11 [00:01<00:01, 3.11it/s]
64%|██████▎ | 7/11 [00:02<00:01, 3.29it/s]
73%|███████▎ | 8/11 [00:02<00:00, 3.22it/s]
82%|████████▏ | 9/11 [00:02<00:00, 3.36it/s]
91%|█████████ | 10/11 [00:03<00:00, 3.40it/s]
100%|██████████| 11/11 [00:03<00:00, 3.53it/s]
100%|██████████| 11/11 [00:03<00:00, 3.29it/s]
0%| | 0/12 [00:00<?, ?it/s]
17%|█▋ | 2/12 [00:00<00:01, 7.56it/s]
25%|██▌ | 3/12 [00:00<00:01, 5.50it/s]
33%|███▎ | 4/12 [00:00<00:02, 3.51it/s]
42%|████▏ | 5/12 [00:01<00:02, 2.42it/s]
50%|█████ | 6/12 [00:02<00:02, 2.10it/s]
58%|█████▊ | 7/12 [00:02<00:02, 2.00it/s]
67%|██████▋ | 8/12 [00:03<00:01, 2.22it/s]
75%|███████▌ | 9/12 [00:03<00:01, 2.22it/s]
83%|████████▎ | 10/12 [00:03<00:00, 2.28it/s]
92%|█████████▏| 11/12 [00:04<00:00, 2.59it/s]
100%|██████████| 12/12 [00:04<00:00, 2.71it/s]
100%|██████████| 12/12 [00:04<00:00, 2.62it/s]
0%| | 0/13 [00:00<?, ?it/s]
15%|█▌ | 2/13 [00:00<00:02, 4.84it/s]
23%|██▎ | 3/13 [00:00<00:02, 3.78it/s]
31%|███ | 4/13 [00:01<00:02, 3.47it/s]
38%|███▊ | 5/13 [00:01<00:02, 3.25it/s]
46%|████▌ | 6/13 [00:01<00:02, 3.17it/s]
54%|█████▍ | 7/13 [00:02<00:01, 3.16it/s]
62%|██████▏ | 8/13 [00:02<00:01, 3.13it/s]
69%|██████▉ | 9/13 [00:02<00:01, 3.20it/s]
77%|███████▋ | 10/13 [00:03<00:00, 3.14it/s]
85%|████████▍ | 11/13 [00:03<00:00, 3.01it/s]
92%|█████████▏| 12/13 [00:03<00:00, 2.57it/s]
100%|██████████| 13/13 [00:04<00:00, 2.18it/s]
100%|██████████| 13/13 [00:04<00:00, 2.86it/s]
0%| | 0/14 [00:00<?, ?it/s]
14%|█▍ | 2/14 [00:00<00:01, 7.57it/s]
21%|██▏ | 3/14 [00:00<00:03, 3.49it/s]
29%|██▊ | 4/14 [00:01<00:03, 2.70it/s]
36%|███▌ | 5/14 [00:01<00:03, 2.44it/s]
43%|████▎ | 6/14 [00:02<00:03, 2.26it/s]
50%|█████ | 7/14 [00:02<00:03, 2.24it/s]
57%|█████▋ | 8/14 [00:03<00:02, 2.37it/s]
64%|██████▍ | 9/14 [00:03<00:01, 2.55it/s]
71%|███████▏ | 10/14 [00:03<00:01, 2.55it/s]
79%|███████▊ | 11/14 [00:04<00:01, 2.62it/s]
86%|████████▌ | 12/14 [00:04<00:00, 2.60it/s]
93%|█████████▎| 13/14 [00:04<00:00, 2.62it/s]
100%|██████████| 14/14 [00:05<00:00, 2.74it/s]
100%|██████████| 14/14 [00:05<00:00, 2.66it/s]
0%| | 0/15 [00:00<?, ?it/s]
13%|█▎ | 2/15 [00:00<00:02, 5.94it/s]
20%|██ | 3/15 [00:00<00:03, 3.88it/s]
27%|██▋ | 4/15 [00:01<00:03, 3.25it/s]
33%|███▎ | 5/15 [00:01<00:03, 3.21it/s]
40%|████ | 6/15 [00:01<00:03, 2.97it/s]
47%|████▋ | 7/15 [00:02<00:02, 3.20it/s]
53%|█████▎ | 8/15 [00:02<00:02, 3.29it/s]
60%|██████ | 9/15 [00:02<00:01, 3.47it/s]
67%|██████▋ | 10/15 [00:02<00:01, 3.58it/s]
73%|███████▎ | 11/15 [00:03<00:01, 3.69it/s]
80%|████████ | 12/15 [00:03<00:00, 3.67it/s]
87%|████████▋ | 13/15 [00:03<00:00, 3.50it/s]
93%|█████████▎| 14/15 [00:04<00:00, 3.18it/s]
100%|██████████| 15/15 [00:04<00:00, 2.76it/s]
100%|██████████| 15/15 [00:04<00:00, 3.28it/s]
| fit_time | score_time | test_precision | test_recall | test_f1 | test_balanced_accuracy | test_roc_auc | test_average_precision | n_observations | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| mean | std | mean | std | mean | std | mean | std | mean | std | mean | std | mean | std | mean | std | mean | std | |
| n_features | ||||||||||||||||||
| 1 | 0.004 | 0.002 | 0.047 | 0.017 | 0.077 | 0.241 | 0.008 | 0.027 | 0.015 | 0.046 | 0.500 | 0.013 | 0.872 | 0.058 | 0.838 | 0.087 | 210.000 | 0.000 |
| 2 | 0.004 | 0.002 | 0.044 | 0.015 | 0.621 | 0.172 | 0.249 | 0.099 | 0.342 | 0.103 | 0.562 | 0.051 | 0.692 | 0.087 | 0.620 | 0.099 | 210.000 | 0.000 |
| 3 | 0.004 | 0.001 | 0.041 | 0.011 | 0.687 | 0.093 | 0.617 | 0.110 | 0.645 | 0.088 | 0.705 | 0.066 | 0.797 | 0.062 | 0.752 | 0.091 | 210.000 | 0.000 |
| 4 | 0.003 | 0.000 | 0.034 | 0.003 | 0.784 | 0.074 | 0.723 | 0.092 | 0.747 | 0.058 | 0.786 | 0.046 | 0.891 | 0.043 | 0.867 | 0.063 | 210.000 | 0.000 |
| 5 | 0.003 | 0.000 | 0.031 | 0.005 | 0.784 | 0.076 | 0.720 | 0.099 | 0.745 | 0.066 | 0.786 | 0.051 | 0.893 | 0.041 | 0.871 | 0.052 | 210.000 | 0.000 |
| 6 | 0.003 | 0.000 | 0.030 | 0.004 | 0.781 | 0.088 | 0.737 | 0.096 | 0.753 | 0.067 | 0.791 | 0.055 | 0.895 | 0.044 | 0.874 | 0.055 | 210.000 | 0.000 |
| 7 | 0.003 | 0.000 | 0.034 | 0.002 | 0.781 | 0.088 | 0.735 | 0.097 | 0.752 | 0.066 | 0.789 | 0.054 | 0.893 | 0.044 | 0.872 | 0.055 | 210.000 | 0.000 |
| 8 | 0.004 | 0.000 | 0.036 | 0.003 | 0.782 | 0.094 | 0.739 | 0.105 | 0.754 | 0.075 | 0.792 | 0.062 | 0.895 | 0.043 | 0.875 | 0.058 | 210.000 | 0.000 |
| 9 | 0.006 | 0.002 | 0.059 | 0.023 | 0.777 | 0.093 | 0.732 | 0.100 | 0.748 | 0.074 | 0.787 | 0.060 | 0.894 | 0.044 | 0.874 | 0.058 | 210.000 | 0.000 |
| 10 | 0.005 | 0.003 | 0.052 | 0.025 | 0.782 | 0.100 | 0.740 | 0.098 | 0.755 | 0.075 | 0.792 | 0.062 | 0.894 | 0.048 | 0.871 | 0.068 | 210.000 | 0.000 |
| 11 | 0.006 | 0.003 | 0.065 | 0.026 | 0.806 | 0.100 | 0.738 | 0.102 | 0.765 | 0.080 | 0.801 | 0.065 | 0.895 | 0.046 | 0.877 | 0.064 | 210.000 | 0.000 |
| 12 | 0.004 | 0.000 | 0.039 | 0.007 | 0.794 | 0.103 | 0.738 | 0.101 | 0.759 | 0.079 | 0.796 | 0.064 | 0.892 | 0.047 | 0.874 | 0.062 | 210.000 | 0.000 |
| 13 | 0.006 | 0.003 | 0.060 | 0.029 | 0.820 | 0.079 | 0.806 | 0.110 | 0.807 | 0.069 | 0.836 | 0.058 | 0.924 | 0.039 | 0.912 | 0.042 | 210.000 | 0.000 |
| 14 | 0.005 | 0.002 | 0.045 | 0.019 | 0.832 | 0.078 | 0.806 | 0.089 | 0.815 | 0.061 | 0.842 | 0.051 | 0.929 | 0.037 | 0.916 | 0.042 | 210.000 | 0.000 |
| 15 | 0.006 | 0.003 | 0.056 | 0.025 | 0.832 | 0.080 | 0.811 | 0.099 | 0.816 | 0.065 | 0.844 | 0.054 | 0.931 | 0.039 | 0.919 | 0.042 | 210.000 | 0.000 |
Using only new features:
0%| | 0/1 [00:00<?, ?it/s]
100%|██████████| 1/1 [00:00<00:00, 832.53it/s]
0%| | 0/2 [00:00<?, ?it/s]
100%|██████████| 2/2 [00:00<00:00, 22.55it/s]
0%| | 0/3 [00:00<?, ?it/s]
67%|██████▋ | 2/3 [00:00<00:00, 18.50it/s]
100%|██████████| 3/3 [00:00<00:00, 17.27it/s]
0%| | 0/4 [00:00<?, ?it/s]
75%|███████▌ | 3/4 [00:00<00:00, 15.22it/s]
100%|██████████| 4/4 [00:00<00:00, 11.89it/s]
0%| | 0/5 [00:00<?, ?it/s]
40%|████ | 2/5 [00:00<00:00, 19.02it/s]
80%|████████ | 4/5 [00:00<00:00, 16.47it/s]
100%|██████████| 5/5 [00:00<00:00, 14.89it/s]
0%| | 0/6 [00:00<?, ?it/s]
33%|███▎ | 2/6 [00:00<00:00, 18.88it/s]
67%|██████▋ | 4/6 [00:00<00:00, 12.39it/s]
100%|██████████| 6/6 [00:00<00:00, 11.03it/s]
100%|██████████| 6/6 [00:00<00:00, 11.68it/s]
0%| | 0/7 [00:00<?, ?it/s]
43%|████▎ | 3/7 [00:00<00:00, 17.53it/s]
71%|███████▏ | 5/7 [00:00<00:00, 16.10it/s]
100%|██████████| 7/7 [00:00<00:00, 15.54it/s]
100%|██████████| 7/7 [00:00<00:00, 15.76it/s]
0%| | 0/8 [00:00<?, ?it/s]
25%|██▌ | 2/8 [00:00<00:00, 19.54it/s]
50%|█████ | 4/8 [00:00<00:00, 12.44it/s]
75%|███████▌ | 6/8 [00:00<00:00, 10.91it/s]
100%|██████████| 8/8 [00:00<00:00, 10.58it/s]
100%|██████████| 8/8 [00:00<00:00, 11.22it/s]
0%| | 0/9 [00:00<?, ?it/s]
22%|██▏ | 2/9 [00:00<00:00, 19.16it/s]
44%|████▍ | 4/9 [00:00<00:00, 13.30it/s]
67%|██████▋ | 6/9 [00:00<00:00, 11.63it/s]
89%|████████▉ | 8/9 [00:00<00:00, 11.94it/s]
100%|██████████| 9/9 [00:00<00:00, 12.86it/s]
0%| | 0/10 [00:00<?, ?it/s]
20%|██ | 2/10 [00:00<00:00, 18.93it/s]
40%|████ | 4/10 [00:00<00:00, 13.08it/s]
60%|██████ | 6/10 [00:00<00:00, 12.21it/s]
80%|████████ | 8/10 [00:00<00:00, 11.59it/s]
100%|██████████| 10/10 [00:00<00:00, 11.14it/s]
100%|██████████| 10/10 [00:00<00:00, 11.77it/s]
0%| | 0/11 [00:00<?, ?it/s]
27%|██▋ | 3/11 [00:00<00:00, 17.62it/s]
45%|████▌ | 5/11 [00:00<00:00, 12.42it/s]
64%|██████▎ | 7/11 [00:00<00:00, 12.38it/s]
82%|████████▏ | 9/11 [00:00<00:00, 12.00it/s]
100%|██████████| 11/11 [00:00<00:00, 12.59it/s]
100%|██████████| 11/11 [00:00<00:00, 12.69it/s]
0%| | 0/12 [00:00<?, ?it/s]
17%|█▋ | 2/12 [00:00<00:00, 19.71it/s]
33%|███▎ | 4/12 [00:00<00:00, 13.60it/s]
50%|█████ | 6/12 [00:00<00:00, 12.93it/s]
67%|██████▋ | 8/12 [00:00<00:00, 12.70it/s]
83%|████████▎ | 10/12 [00:00<00:00, 13.03it/s]
100%|██████████| 12/12 [00:00<00:00, 12.44it/s]
100%|██████████| 12/12 [00:00<00:00, 12.91it/s]
0%| | 0/13 [00:00<?, ?it/s]
23%|██▎ | 3/13 [00:00<00:00, 20.65it/s]
46%|████▌ | 6/13 [00:00<00:00, 17.56it/s]
62%|██████▏ | 8/13 [00:00<00:00, 16.39it/s]
77%|███████▋ | 10/13 [00:00<00:00, 16.13it/s]
92%|█████████▏| 12/13 [00:00<00:00, 15.96it/s]
100%|██████████| 13/13 [00:00<00:00, 16.33it/s]
0%| | 0/14 [00:00<?, ?it/s]
14%|█▍ | 2/14 [00:00<00:00, 16.70it/s]
29%|██▊ | 4/14 [00:00<00:00, 10.02it/s]
43%|████▎ | 6/14 [00:00<00:00, 9.31it/s]
57%|█████▋ | 8/14 [00:00<00:00, 9.26it/s]
64%|██████▍ | 9/14 [00:00<00:00, 9.31it/s]
71%|███████▏ | 10/14 [00:01<00:00, 9.36it/s]
86%|████████▌ | 12/14 [00:01<00:00, 10.79it/s]
100%|██████████| 14/14 [00:01<00:00, 12.13it/s]
100%|██████████| 14/14 [00:01<00:00, 10.67it/s]
0%| | 0/15 [00:00<?, ?it/s]
13%|█▎ | 2/15 [00:00<00:00, 18.64it/s]
27%|██▋ | 4/15 [00:00<00:00, 11.49it/s]
40%|████ | 6/15 [00:00<00:00, 9.74it/s]
53%|█████▎ | 8/15 [00:00<00:00, 9.15it/s]
60%|██████ | 9/15 [00:00<00:00, 8.95it/s]
67%|██████▋ | 10/15 [00:01<00:00, 8.87it/s]
73%|███████▎ | 11/15 [00:01<00:00, 8.58it/s]
80%|████████ | 12/15 [00:01<00:00, 8.50it/s]
93%|█████████▎| 14/15 [00:01<00:00, 9.32it/s]
100%|██████████| 15/15 [00:01<00:00, 9.51it/s]
| fit_time | score_time | test_precision | test_recall | test_f1 | test_balanced_accuracy | test_roc_auc | test_average_precision | n_observations | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| mean | std | mean | std | mean | std | mean | std | mean | std | mean | std | mean | std | mean | std | mean | std | |
| n_features | ||||||||||||||||||
| 1 | 0.003 | 0.001 | 0.037 | 0.012 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.500 | 0.000 | 0.751 | 0.067 | 0.695 | 0.085 | 210.000 | 0.000 |
| 2 | 0.006 | 0.003 | 0.065 | 0.028 | 0.624 | 0.089 | 0.480 | 0.109 | 0.535 | 0.085 | 0.632 | 0.054 | 0.702 | 0.063 | 0.657 | 0.070 | 210.000 | 0.000 |
| 3 | 0.004 | 0.002 | 0.044 | 0.015 | 0.620 | 0.095 | 0.538 | 0.095 | 0.570 | 0.076 | 0.646 | 0.060 | 0.755 | 0.058 | 0.731 | 0.058 | 210.000 | 0.000 |
| 4 | 0.005 | 0.003 | 0.059 | 0.028 | 0.722 | 0.094 | 0.669 | 0.107 | 0.688 | 0.078 | 0.738 | 0.061 | 0.811 | 0.051 | 0.769 | 0.062 | 210.000 | 0.000 |
| 5 | 0.004 | 0.001 | 0.039 | 0.008 | 0.713 | 0.104 | 0.647 | 0.104 | 0.671 | 0.076 | 0.724 | 0.061 | 0.830 | 0.052 | 0.793 | 0.071 | 210.000 | 0.000 |
| 6 | 0.006 | 0.002 | 0.062 | 0.023 | 0.724 | 0.099 | 0.657 | 0.107 | 0.680 | 0.070 | 0.732 | 0.053 | 0.831 | 0.050 | 0.790 | 0.074 | 210.000 | 0.000 |
| 7 | 0.004 | 0.002 | 0.046 | 0.015 | 0.723 | 0.104 | 0.649 | 0.112 | 0.675 | 0.072 | 0.729 | 0.056 | 0.827 | 0.049 | 0.788 | 0.070 | 210.000 | 0.000 |
| 8 | 0.005 | 0.003 | 0.055 | 0.026 | 0.711 | 0.101 | 0.628 | 0.112 | 0.658 | 0.078 | 0.717 | 0.057 | 0.827 | 0.052 | 0.782 | 0.074 | 210.000 | 0.000 |
| 9 | 0.004 | 0.002 | 0.042 | 0.013 | 0.710 | 0.100 | 0.631 | 0.114 | 0.660 | 0.080 | 0.718 | 0.059 | 0.824 | 0.052 | 0.777 | 0.074 | 210.000 | 0.000 |
| 10 | 0.007 | 0.003 | 0.067 | 0.025 | 0.709 | 0.097 | 0.624 | 0.114 | 0.656 | 0.081 | 0.715 | 0.058 | 0.820 | 0.051 | 0.774 | 0.074 | 210.000 | 0.000 |
| 11 | 0.005 | 0.002 | 0.049 | 0.017 | 0.705 | 0.096 | 0.626 | 0.114 | 0.654 | 0.076 | 0.714 | 0.055 | 0.817 | 0.051 | 0.769 | 0.074 | 210.000 | 0.000 |
| 12 | 0.006 | 0.003 | 0.059 | 0.025 | 0.680 | 0.103 | 0.613 | 0.111 | 0.637 | 0.080 | 0.697 | 0.060 | 0.811 | 0.054 | 0.765 | 0.074 | 210.000 | 0.000 |
| 13 | 0.005 | 0.004 | 0.051 | 0.025 | 0.678 | 0.093 | 0.617 | 0.110 | 0.639 | 0.080 | 0.699 | 0.060 | 0.809 | 0.054 | 0.758 | 0.076 | 210.000 | 0.000 |
| 14 | 0.004 | 0.001 | 0.041 | 0.011 | 0.717 | 0.103 | 0.630 | 0.102 | 0.663 | 0.070 | 0.720 | 0.055 | 0.816 | 0.056 | 0.764 | 0.077 | 210.000 | 0.000 |
| 15 | 0.004 | 0.002 | 0.042 | 0.018 | 0.711 | 0.090 | 0.670 | 0.109 | 0.682 | 0.070 | 0.731 | 0.056 | 0.825 | 0.056 | 0.771 | 0.078 | 210.000 | 0.000 |
Best number of features by subset of the data:#
| ald | all | new | |
|---|---|---|---|
| fit_time | 5 | 11 | 10 |
| score_time | 5 | 11 | 10 |
| test_precision | 1 | 15 | 6 |
| test_recall | 11 | 15 | 15 |
| test_f1 | 10 | 15 | 4 |
| test_balanced_accuracy | 10 | 15 | 4 |
| test_roc_auc | 14 | 15 | 6 |
| test_average_precision | 14 | 15 | 5 |
| n_observations | 1 | 1 | 1 |
Train, test split#
Show number of cases in train and test data
| train | test | |
|---|---|---|
| False | 98 | 24 |
| True | 70 | 18 |
Results#
run_modelreturns dataclasses with the further needed resultsadd mrmr selection of data (select best number of features to use instead of fixing it)
Save results for final model on entire data, new features and ALD study criteria selected data.
0%| | 0/15 [00:00<?, ?it/s]
13%|█▎ | 2/15 [00:00<00:02, 5.89it/s]
20%|██ | 3/15 [00:00<00:02, 4.07it/s]
27%|██▋ | 4/15 [00:01<00:02, 3.69it/s]
33%|███▎ | 5/15 [00:01<00:02, 3.50it/s]
40%|████ | 6/15 [00:01<00:02, 3.33it/s]
47%|████▋ | 7/15 [00:01<00:02, 3.25it/s]
53%|█████▎ | 8/15 [00:02<00:02, 3.17it/s]
60%|██████ | 9/15 [00:02<00:01, 3.21it/s]
67%|██████▋ | 10/15 [00:02<00:01, 3.13it/s]
73%|███████▎ | 11/15 [00:03<00:01, 2.66it/s]
80%|████████ | 12/15 [00:04<00:01, 2.23it/s]
87%|████████▋ | 13/15 [00:04<00:00, 2.01it/s]
93%|█████████▎| 14/15 [00:05<00:00, 1.86it/s]
100%|██████████| 15/15 [00:05<00:00, 1.94it/s]
100%|██████████| 15/15 [00:05<00:00, 2.60it/s]
0%| | 0/6 [00:00<?, ?it/s]
50%|█████ | 3/6 [00:00<00:00, 21.96it/s]
100%|██████████| 6/6 [00:00<00:00, 14.86it/s]
100%|██████████| 6/6 [00:00<00:00, 15.45it/s]
0%| | 0/14 [00:00<?, ?it/s]
14%|█▍ | 2/14 [00:00<00:01, 7.00it/s]
21%|██▏ | 3/14 [00:00<00:01, 5.53it/s]
29%|██▊ | 4/14 [00:00<00:01, 5.05it/s]
36%|███▌ | 5/14 [00:00<00:01, 4.82it/s]
43%|████▎ | 6/14 [00:01<00:01, 4.31it/s]
50%|█████ | 7/14 [00:01<00:01, 4.38it/s]
57%|█████▋ | 8/14 [00:01<00:01, 4.34it/s]
64%|██████▍ | 9/14 [00:01<00:01, 4.06it/s]
71%|███████▏ | 10/14 [00:02<00:01, 2.92it/s]
79%|███████▊ | 11/14 [00:03<00:01, 2.52it/s]
86%|████████▌ | 12/14 [00:03<00:00, 2.30it/s]
93%|█████████▎| 13/14 [00:04<00:00, 2.18it/s]
100%|██████████| 14/14 [00:04<00:00, 2.17it/s]
100%|██████████| 14/14 [00:04<00:00, 3.06it/s]
ROC-AUC on test split#
pimmslearn.plotting - INFO Saved Figures to runs/alzheimer_study/diff_analysis/AD/PI_vs_DAE/auc_roc_curve.pdf
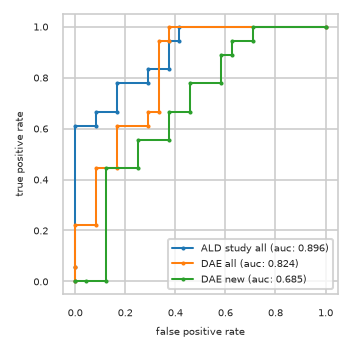
Data used to plot ROC:
| ALD study all | DAE all | DAE new | ||||
|---|---|---|---|---|---|---|
| fpr | tpr | fpr | tpr | fpr | tpr | |
| 0 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| 1 | 0.000 | 0.056 | 0.000 | 0.056 | 0.042 | 0.000 |
| 2 | 0.000 | 0.611 | 0.000 | 0.222 | 0.125 | 0.000 |
| 3 | 0.083 | 0.611 | 0.083 | 0.222 | 0.125 | 0.444 |
| 4 | 0.083 | 0.667 | 0.083 | 0.444 | 0.250 | 0.444 |
| 5 | 0.167 | 0.667 | 0.167 | 0.444 | 0.250 | 0.556 |
| 6 | 0.167 | 0.778 | 0.167 | 0.611 | 0.375 | 0.556 |
| 7 | 0.292 | 0.778 | 0.292 | 0.611 | 0.375 | 0.667 |
| 8 | 0.292 | 0.833 | 0.292 | 0.667 | 0.458 | 0.667 |
| 9 | 0.375 | 0.833 | 0.333 | 0.667 | 0.458 | 0.778 |
| 10 | 0.375 | 0.944 | 0.333 | 0.944 | 0.583 | 0.778 |
| 11 | 0.417 | 0.944 | 0.375 | 0.944 | 0.583 | 0.889 |
| 12 | 0.417 | 1.000 | 0.375 | 1.000 | 0.625 | 0.889 |
| 13 | 1.000 | 1.000 | 1.000 | 1.000 | 0.625 | 0.944 |
| 14 | NaN | NaN | NaN | NaN | 0.708 | 0.944 |
| 15 | NaN | NaN | NaN | NaN | 0.708 | 1.000 |
| 16 | NaN | NaN | NaN | NaN | 1.000 | 1.000 |
Features selected for final models#
| ALD study all | DAE all | DAE new | |
|---|---|---|---|
| rank | |||
| 0 | P10636-2;P10636-6 | P10636-2;P10636-6 | Q14894 |
| 1 | O75051;O75051-2 | P22676 | P01704 |
| 2 | O95428;O95428-5;O95428-6 | Q14894 | F8WBF9;Q5TH30;Q9UGV2;Q9UGV2-2;Q9UGV2-3 |
| 3 | P61981 | P63104 | P31321 |
| 4 | P14174 | Q9Y2T3;Q9Y2T3-3 | P51674;P51674-2;P51674-3 |
| 5 | P04075 | A0A0A0MRJ7;P12259 | P07900;P07900-2 |
| 6 | A0A0C4DGY8;D6RA00;Q9UHY7 | P04075 | None |
| 7 | P08294 | P61981 | None |
| 8 | Q9Y2T3;Q9Y2T3-3 | P14174 | None |
| 9 | P00338;P00338-3 | P00492 | None |
| 10 | Q13231;Q13231-3 | P25189;P25189-2 | None |
| 11 | C9JF17;P05090 | P00338;P00338-3 | None |
| 12 | P14618 | Q6EMK4 | None |
| 13 | Q6EMK4 | A0A0C4DGY8;D6RA00;Q9UHY7 | None |
| 14 | None | P31321 | None |
Precision-Recall plot on test data#
pimmslearn.plotting - INFO Saved Figures to runs/alzheimer_study/diff_analysis/AD/PI_vs_DAE/prec_recall_curve.pdf
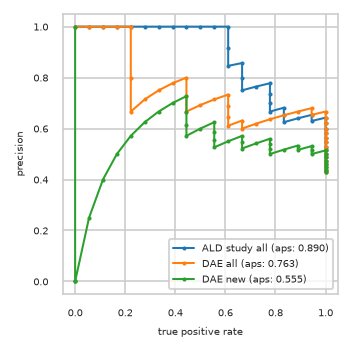
Data used to plot PRC:
| ALD study all | DAE all | DAE new | ||||
|---|---|---|---|---|---|---|
| precision | tpr | precision | tpr | precision | tpr | |
| 0 | 0.429 | 1.000 | 0.429 | 1.000 | 0.429 | 1.000 |
| 1 | 0.439 | 1.000 | 0.439 | 1.000 | 0.439 | 1.000 |
| 2 | 0.450 | 1.000 | 0.450 | 1.000 | 0.450 | 1.000 |
| 3 | 0.462 | 1.000 | 0.462 | 1.000 | 0.462 | 1.000 |
| 4 | 0.474 | 1.000 | 0.474 | 1.000 | 0.474 | 1.000 |
| 5 | 0.486 | 1.000 | 0.486 | 1.000 | 0.486 | 1.000 |
| 6 | 0.500 | 1.000 | 0.500 | 1.000 | 0.500 | 1.000 |
| 7 | 0.514 | 1.000 | 0.514 | 1.000 | 0.514 | 1.000 |
| 8 | 0.529 | 1.000 | 0.529 | 1.000 | 0.500 | 0.944 |
| 9 | 0.545 | 1.000 | 0.545 | 1.000 | 0.515 | 0.944 |
| 10 | 0.562 | 1.000 | 0.562 | 1.000 | 0.531 | 0.944 |
| 11 | 0.581 | 1.000 | 0.581 | 1.000 | 0.516 | 0.889 |
| 12 | 0.600 | 1.000 | 0.600 | 1.000 | 0.533 | 0.889 |
| 13 | 0.621 | 1.000 | 0.621 | 1.000 | 0.517 | 0.833 |
| 14 | 0.643 | 1.000 | 0.643 | 1.000 | 0.500 | 0.778 |
| 15 | 0.630 | 0.944 | 0.667 | 1.000 | 0.519 | 0.778 |
| 16 | 0.654 | 0.944 | 0.654 | 0.944 | 0.538 | 0.778 |
| 17 | 0.640 | 0.889 | 0.680 | 0.944 | 0.560 | 0.778 |
| 18 | 0.625 | 0.833 | 0.667 | 0.889 | 0.542 | 0.722 |
| 19 | 0.652 | 0.833 | 0.652 | 0.833 | 0.522 | 0.667 |
| 20 | 0.682 | 0.833 | 0.636 | 0.778 | 0.545 | 0.667 |
| 21 | 0.667 | 0.778 | 0.619 | 0.722 | 0.571 | 0.667 |
| 22 | 0.700 | 0.778 | 0.600 | 0.667 | 0.550 | 0.611 |
| 23 | 0.737 | 0.778 | 0.632 | 0.667 | 0.526 | 0.556 |
| 24 | 0.778 | 0.778 | 0.611 | 0.611 | 0.556 | 0.556 |
| 25 | 0.765 | 0.722 | 0.647 | 0.611 | 0.588 | 0.556 |
| 26 | 0.750 | 0.667 | 0.688 | 0.611 | 0.625 | 0.556 |
| 27 | 0.800 | 0.667 | 0.733 | 0.611 | 0.600 | 0.500 |
| 28 | 0.857 | 0.667 | 0.714 | 0.556 | 0.571 | 0.444 |
| 29 | 0.846 | 0.611 | 0.692 | 0.500 | 0.615 | 0.444 |
| 30 | 0.917 | 0.611 | 0.667 | 0.444 | 0.667 | 0.444 |
| 31 | 1.000 | 0.611 | 0.727 | 0.444 | 0.727 | 0.444 |
| 32 | 1.000 | 0.556 | 0.800 | 0.444 | 0.700 | 0.389 |
| 33 | 1.000 | 0.500 | 0.778 | 0.389 | 0.667 | 0.333 |
| 34 | 1.000 | 0.444 | 0.750 | 0.333 | 0.625 | 0.278 |
| 35 | 1.000 | 0.389 | 0.714 | 0.278 | 0.571 | 0.222 |
| 36 | 1.000 | 0.333 | 0.667 | 0.222 | 0.500 | 0.167 |
| 37 | 1.000 | 0.278 | 0.800 | 0.222 | 0.400 | 0.111 |
| 38 | 1.000 | 0.222 | 1.000 | 0.222 | 0.250 | 0.056 |
| 39 | 1.000 | 0.167 | 1.000 | 0.167 | 0.000 | 0.000 |
| 40 | 1.000 | 0.111 | 1.000 | 0.111 | 0.000 | 0.000 |
| 41 | 1.000 | 0.056 | 1.000 | 0.056 | 0.000 | 0.000 |
| 42 | 1.000 | 0.000 | 1.000 | 0.000 | 1.000 | 0.000 |
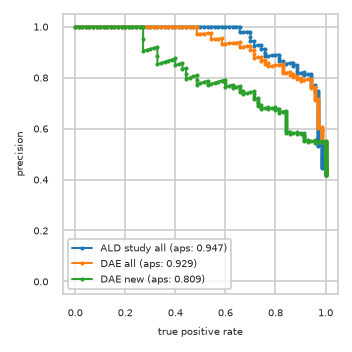
Train data plots#
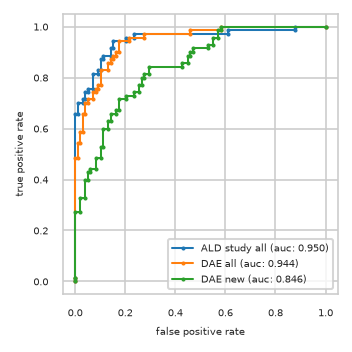
pimmslearn.plotting - INFO Saved Figures to runs/alzheimer_study/diff_analysis/AD/PI_vs_DAE/prec_recall_curve_train.pdf
pimmslearn.plotting - INFO Saved Figures to runs/alzheimer_study/diff_analysis/AD/PI_vs_DAE/auc_roc_curve_train.pdf
Output files:
{'results_DAE all.pkl': PosixPath('runs/alzheimer_study/diff_analysis/AD/PI_vs_DAE/results_DAE all.pkl'),
'results_DAE new.pkl': PosixPath('runs/alzheimer_study/diff_analysis/AD/PI_vs_DAE/results_DAE new.pkl'),
'results_ALD study all.pkl': PosixPath('runs/alzheimer_study/diff_analysis/AD/PI_vs_DAE/results_ALD study all.pkl'),
'auc_roc_curve.pdf': PosixPath('runs/alzheimer_study/diff_analysis/AD/PI_vs_DAE/auc_roc_curve.pdf'),
'mrmr_feat_by_model.xlsx': PosixPath('runs/alzheimer_study/diff_analysis/AD/PI_vs_DAE/mrmr_feat_by_model.xlsx'),
'prec_recall_curve.pdf': PosixPath('runs/alzheimer_study/diff_analysis/AD/PI_vs_DAE/prec_recall_curve.pdf'),
'prec_recall_curve_train.pdf': PosixPath('runs/alzheimer_study/diff_analysis/AD/PI_vs_DAE/prec_recall_curve_train.pdf'),
'auc_roc_curve_train.pdf': PosixPath('runs/alzheimer_study/diff_analysis/AD/PI_vs_DAE/auc_roc_curve_train.pdf')}