Compare outcomes from differential analysis based on different imputation methods#
load scores based on
10_1_ald_diff_analysis
Parameters#
Default and set parameters for the notebook.
folder_experiment = 'runs/appl_ald_data/plasma/proteinGroups'
target = 'kleiner'
model_key = 'VAE'
baseline = 'RSN'
out_folder = 'diff_analysis'
selected_statistics = ['p-unc', '-Log10 pvalue', 'qvalue', 'rejected']
disease_ontology = 5082 # code from https://disease-ontology.org/
# split diseases notebook? Query gene names for proteins in file from uniprot?
annotaitons_gene_col = 'PG.Genes'
# Parameters
disease_ontology = 10652
folder_experiment = "runs/alzheimer_study"
target = "AD"
baseline = "PI"
model_key = "RF"
out_folder = "diff_analysis"
annotaitons_gene_col = "None"
Add set parameters to configuration
root - INFO Removed from global namespace: folder_experiment
root - INFO Removed from global namespace: target
root - INFO Removed from global namespace: model_key
root - INFO Removed from global namespace: baseline
root - INFO Removed from global namespace: out_folder
root - INFO Removed from global namespace: selected_statistics
root - INFO Removed from global namespace: disease_ontology
root - INFO Removed from global namespace: annotaitons_gene_col
root - INFO Already set attribute: folder_experiment has value runs/alzheimer_study
root - INFO Already set attribute: out_folder has value diff_analysis
{'annotaitons_gene_col': 'None',
'baseline': 'PI',
'data': PosixPath('runs/alzheimer_study/data'),
'disease_ontology': 10652,
'folder_experiment': PosixPath('runs/alzheimer_study'),
'freq_features_observed': PosixPath('runs/alzheimer_study/freq_features_observed.csv'),
'model_key': 'RF',
'out_figures': PosixPath('runs/alzheimer_study/figures'),
'out_folder': PosixPath('runs/alzheimer_study/diff_analysis/AD/PI_vs_RF'),
'out_metrics': PosixPath('runs/alzheimer_study'),
'out_models': PosixPath('runs/alzheimer_study'),
'out_preds': PosixPath('runs/alzheimer_study/preds'),
'scores_folder': PosixPath('runs/alzheimer_study/diff_analysis/AD/scores'),
'selected_statistics': ['p-unc', '-Log10 pvalue', 'qvalue', 'rejected'],
'target': 'AD'}
Excel file for exports#
files_out = dict()
writer_args = dict(float_format='%.3f')
fname = args.out_folder / 'diff_analysis_compare_methods.xlsx'
files_out[fname.name] = fname
writer = pd.ExcelWriter(fname)
logger.info("Writing to excel file: %s", fname)
root - INFO Writing to excel file: runs/alzheimer_study/diff_analysis/AD/PI_vs_RF/diff_analysis_compare_methods.xlsx
Load scores#
Load baseline model scores#
Show all statistics, later use selected statistics
| model | PI | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| var | SS | DF | F | p-unc | np2 | -Log10 pvalue | qvalue | rejected | |
| protein groups | Source | ||||||||
| A0A024QZX5;A0A087X1N8;P35237 | AD | 0.833 | 1 | 1.390 | 0.240 | 0.007 | 0.620 | 0.397 | False |
| age | 0.147 | 1 | 0.246 | 0.620 | 0.001 | 0.207 | 0.750 | False | |
| Kiel | 2.439 | 1 | 4.072 | 0.045 | 0.021 | 1.347 | 0.112 | False | |
| Magdeburg | 4.762 | 1 | 7.949 | 0.005 | 0.040 | 2.274 | 0.020 | True | |
| Sweden | 8.268 | 1 | 13.800 | 0.000 | 0.067 | 3.574 | 0.002 | True | |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| S4R3U6 | AD | 0.531 | 1 | 0.525 | 0.469 | 0.003 | 0.328 | 0.623 | False |
| age | 1.792 | 1 | 1.774 | 0.185 | 0.009 | 0.734 | 0.328 | False | |
| Kiel | 0.002 | 1 | 0.002 | 0.961 | 0.000 | 0.017 | 0.976 | False | |
| Magdeburg | 2.675 | 1 | 2.648 | 0.105 | 0.014 | 0.978 | 0.218 | False | |
| Sweden | 15.376 | 1 | 15.221 | 0.000 | 0.074 | 3.878 | 0.001 | True | |
7105 rows × 8 columns
Load selected comparison model scores#
| model | RF | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| var | SS | DF | F | p-unc | np2 | -Log10 pvalue | qvalue | rejected | |
| protein groups | Source | ||||||||
| A0A024QZX5;A0A087X1N8;P35237 | AD | 1.010 | 1 | 7.629 | 0.006 | 0.038 | 2.200 | 0.019 | True |
| age | 0.002 | 1 | 0.017 | 0.896 | 0.000 | 0.048 | 0.934 | False | |
| Kiel | 0.206 | 1 | 1.559 | 0.213 | 0.008 | 0.671 | 0.339 | False | |
| Magdeburg | 0.388 | 1 | 2.933 | 0.088 | 0.015 | 1.053 | 0.169 | False | |
| Sweden | 1.521 | 1 | 11.489 | 0.001 | 0.057 | 3.070 | 0.003 | True | |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| S4R3U6 | AD | 1.041 | 1 | 2.252 | 0.135 | 0.012 | 0.869 | 0.238 | False |
| age | 0.807 | 1 | 1.746 | 0.188 | 0.009 | 0.726 | 0.308 | False | |
| Kiel | 1.830 | 1 | 3.958 | 0.048 | 0.020 | 1.318 | 0.103 | False | |
| Magdeburg | 1.832 | 1 | 3.963 | 0.048 | 0.020 | 1.319 | 0.103 | False | |
| Sweden | 12.678 | 1 | 27.419 | 0.000 | 0.126 | 6.367 | 0.000 | True | |
7105 rows × 8 columns
Combined scores#
show only selected statistics for comparsion
| model | PI | RF | |||||||
|---|---|---|---|---|---|---|---|---|---|
| var | p-unc | -Log10 pvalue | qvalue | rejected | p-unc | -Log10 pvalue | qvalue | rejected | |
| protein groups | Source | ||||||||
| A0A024QZX5;A0A087X1N8;P35237 | AD | 0.240 | 0.620 | 0.397 | False | 0.006 | 2.200 | 0.019 | True |
| Kiel | 0.045 | 1.347 | 0.112 | False | 0.213 | 0.671 | 0.339 | False | |
| Magdeburg | 0.005 | 2.274 | 0.020 | True | 0.088 | 1.053 | 0.169 | False | |
| Sweden | 0.000 | 3.574 | 0.002 | True | 0.001 | 3.070 | 0.003 | True | |
| age | 0.620 | 0.207 | 0.750 | False | 0.896 | 0.048 | 0.934 | False | |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| S4R3U6 | AD | 0.469 | 0.328 | 0.623 | False | 0.135 | 0.869 | 0.238 | False |
| Kiel | 0.961 | 0.017 | 0.976 | False | 0.048 | 1.318 | 0.103 | False | |
| Magdeburg | 0.105 | 0.978 | 0.218 | False | 0.048 | 1.319 | 0.103 | False | |
| Sweden | 0.000 | 3.878 | 0.001 | True | 0.000 | 6.367 | 0.000 | True | |
| age | 0.185 | 0.734 | 0.328 | False | 0.188 | 0.726 | 0.308 | False | |
7105 rows × 8 columns
Models in comparison (name mapping)
{'PI': 'PI', 'RF': 'RF'}
Describe scores#
| model | PI | RF | ||||
|---|---|---|---|---|---|---|
| var | p-unc | -Log10 pvalue | qvalue | p-unc | -Log10 pvalue | qvalue |
| count | 7,105.000 | 7,105.000 | 7,105.000 | 7,105.000 | 7,105.000 | 7,105.000 |
| mean | 0.261 | 2.476 | 0.338 | 0.233 | 3.079 | 0.291 |
| std | 0.303 | 5.328 | 0.331 | 0.295 | 5.788 | 0.323 |
| min | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| 25% | 0.004 | 0.335 | 0.016 | 0.001 | 0.388 | 0.003 |
| 50% | 0.121 | 0.916 | 0.243 | 0.071 | 1.149 | 0.142 |
| 75% | 0.463 | 2.411 | 0.617 | 0.409 | 3.086 | 0.546 |
| max | 0.999 | 146.241 | 0.999 | 1.000 | 84.835 | 1.000 |
One to one comparison of by feature:#
/tmp/ipykernel_88901/3761369923.py:2: FutureWarning: Starting with pandas version 3.0 all arguments of to_excel except for the argument 'excel_writer' will be keyword-only.
scores.to_excel(writer, 'scores', **writer_args)
| model | PI | RF | |||||||
|---|---|---|---|---|---|---|---|---|---|
| var | p-unc | -Log10 pvalue | qvalue | rejected | p-unc | -Log10 pvalue | qvalue | rejected | |
| protein groups | Source | ||||||||
| A0A024QZX5;A0A087X1N8;P35237 | AD | 0.240 | 0.620 | 0.397 | False | 0.006 | 2.200 | 0.019 | True |
| A0A024R0T9;K7ER74;P02655 | AD | 0.059 | 1.228 | 0.139 | False | 0.031 | 1.511 | 0.072 | False |
| A0A024R3W6;A0A024R412;O60462;O60462-2;O60462-3;O60462-4;O60462-5;Q7LBX6;X5D2Q8 | AD | 0.040 | 1.393 | 0.103 | False | 0.403 | 0.395 | 0.540 | False |
| A0A024R644;A0A0A0MRU5;A0A1B0GWI2;O75503 | AD | 0.420 | 0.377 | 0.580 | False | 0.257 | 0.591 | 0.390 | False |
| A0A075B6H7 | AD | 0.027 | 1.567 | 0.075 | False | 0.009 | 2.051 | 0.026 | True |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| Q9Y6R7 | AD | 0.175 | 0.756 | 0.316 | False | 0.175 | 0.756 | 0.292 | False |
| Q9Y6X5 | AD | 0.070 | 1.155 | 0.159 | False | 0.203 | 0.692 | 0.327 | False |
| Q9Y6Y8;Q9Y6Y8-2 | AD | 0.083 | 1.079 | 0.182 | False | 0.083 | 1.079 | 0.162 | False |
| Q9Y6Y9 | AD | 0.348 | 0.459 | 0.512 | False | 0.328 | 0.484 | 0.468 | False |
| S4R3U6 | AD | 0.469 | 0.328 | 0.623 | False | 0.135 | 0.869 | 0.238 | False |
1421 rows × 8 columns
And the descriptive statistics of the numeric values:
| model | PI | RF | ||||
|---|---|---|---|---|---|---|
| var | p-unc | -Log10 pvalue | qvalue | p-unc | -Log10 pvalue | qvalue |
| count | 1,421.000 | 1,421.000 | 1,421.000 | 1,421.000 | 1,421.000 | 1,421.000 |
| mean | 0.252 | 1.411 | 0.334 | 0.246 | 1.519 | 0.311 |
| std | 0.291 | 1.654 | 0.316 | 0.293 | 1.759 | 0.317 |
| min | 0.000 | 0.001 | 0.000 | 0.000 | 0.001 | 0.000 |
| 25% | 0.013 | 0.368 | 0.041 | 0.009 | 0.374 | 0.027 |
| 50% | 0.121 | 0.917 | 0.242 | 0.101 | 0.997 | 0.188 |
| 75% | 0.428 | 1.899 | 0.588 | 0.423 | 2.030 | 0.559 |
| max | 0.999 | 25.104 | 0.999 | 0.998 | 18.758 | 0.998 |
and the boolean decision values
| model | PI | RF |
|---|---|---|
| var | rejected | rejected |
| count | 1421 | 1421 |
| unique | 2 | 2 |
| top | False | False |
| freq | 1031 | 961 |
Load frequencies of observed features#
| data | |
|---|---|
| frequency | |
| protein groups | |
| A0A024QZX5;A0A087X1N8;P35237 | 186 |
| A0A024R0T9;K7ER74;P02655 | 195 |
| A0A024R3W6;A0A024R412;O60462;O60462-2;O60462-3;O60462-4;O60462-5;Q7LBX6;X5D2Q8 | 174 |
| A0A024R644;A0A0A0MRU5;A0A1B0GWI2;O75503 | 196 |
| A0A075B6H7 | 91 |
| ... | ... |
| Q9Y6R7 | 197 |
| Q9Y6X5 | 173 |
| Q9Y6Y8;Q9Y6Y8-2 | 197 |
| Q9Y6Y9 | 119 |
| S4R3U6 | 126 |
1421 rows × 1 columns
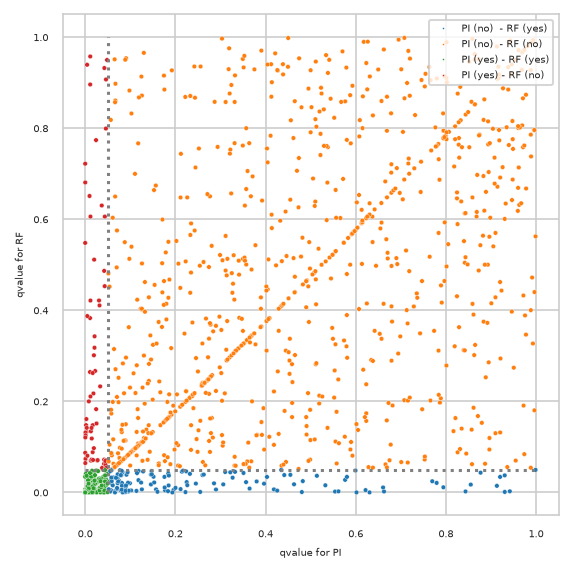
Plot qvalues of both models with annotated decisions#
Prepare data for plotting (qvalues)
| PI | RF | frequency | Differential Analysis Comparison | |
|---|---|---|---|---|
| protein groups | ||||
| A0A024QZX5;A0A087X1N8;P35237 | 0.397 | 0.019 | 186 | PI (no) - RF (yes) |
| A0A024R0T9;K7ER74;P02655 | 0.139 | 0.072 | 195 | PI (no) - RF (no) |
| A0A024R3W6;A0A024R412;O60462;O60462-2;O60462-3;O60462-4;O60462-5;Q7LBX6;X5D2Q8 | 0.103 | 0.540 | 174 | PI (no) - RF (no) |
| A0A024R644;A0A0A0MRU5;A0A1B0GWI2;O75503 | 0.580 | 0.390 | 196 | PI (no) - RF (no) |
| A0A075B6H7 | 0.075 | 0.026 | 91 | PI (no) - RF (yes) |
| ... | ... | ... | ... | ... |
| Q9Y6R7 | 0.316 | 0.292 | 197 | PI (no) - RF (no) |
| Q9Y6X5 | 0.159 | 0.327 | 173 | PI (no) - RF (no) |
| Q9Y6Y8;Q9Y6Y8-2 | 0.182 | 0.162 | 197 | PI (no) - RF (no) |
| Q9Y6Y9 | 0.512 | 0.468 | 119 | PI (no) - RF (no) |
| S4R3U6 | 0.623 | 0.238 | 126 | PI (no) - RF (no) |
1421 rows × 4 columns
List of features with the highest difference in qvalues
| PI | RF | frequency | Differential Analysis Comparison | diff_qvalue | |
|---|---|---|---|---|---|
| protein groups | |||||
| P55268 | 0.999 | 0.049 | 194 | PI (no) - RF (yes) | 0.949 |
| F6VDH7;P50502;Q3KNR6 | 0.011 | 0.958 | 175 | PI (yes) - RF (no) | 0.946 |
| P17302 | 0.942 | 0.002 | 135 | PI (no) - RF (yes) | 0.939 |
| A0A087X1Z2;C9JTV4;H0Y4Y4;Q8WYH2;Q96C19;Q9BUP0;Q9BUP0-2 | 0.004 | 0.939 | 66 | PI (yes) - RF (no) | 0.935 |
| A0A087WU43;A0A087WX17;A0A087WXI5;P12830;P12830-2 | 0.931 | 0.001 | 134 | PI (no) - RF (yes) | 0.929 |
| ... | ... | ... | ... | ... | ... |
| O15354 | 0.059 | 0.050 | 197 | PI (no) - RF (yes) | 0.009 |
| Q9NX62 | 0.056 | 0.047 | 197 | PI (no) - RF (yes) | 0.009 |
| P00740;P00740-2 | 0.053 | 0.044 | 197 | PI (no) - RF (yes) | 0.008 |
| K7ERG9;P00746 | 0.052 | 0.044 | 197 | PI (no) - RF (yes) | 0.008 |
| Q16706 | 0.046 | 0.054 | 195 | PI (yes) - RF (no) | 0.008 |
200 rows × 5 columns
Differences plotted with created annotations#
pimmslearn.plotting - INFO Saved Figures to runs/alzheimer_study/diff_analysis/AD/PI_vs_RF/diff_analysis_comparision_1_RF
also showing how many features were measured (“observed”) by size of circle
pimmslearn.plotting - INFO Saved Figures to runs/alzheimer_study/diff_analysis/AD/PI_vs_RF/diff_analysis_comparision_2_RF
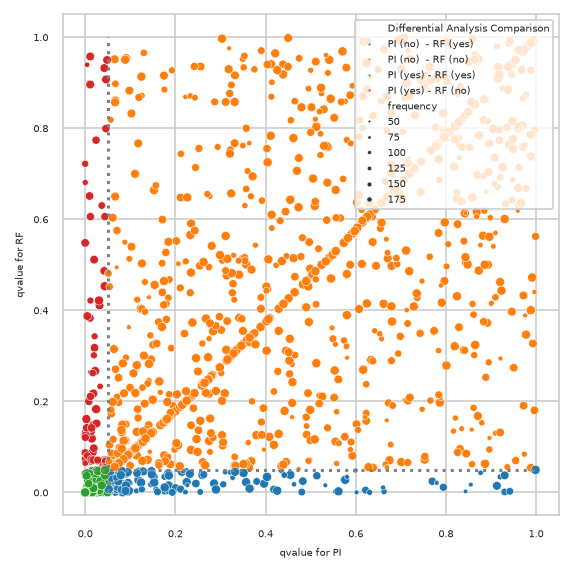
Only features contained in model#
this block exist due to a specific part in the ALD analysis of the paper
root - INFO No features only in new comparision model.
DISEASES DB lookup#
Query diseases database for gene associations with specified disease ontology id.
pimmslearn.databases.diseases - WARNING There are more associations available
| ENSP | score | |
|---|---|---|
| None | ||
| APP | ENSP00000284981 | 5.000 |
| PSEN2 | ENSP00000355747 | 5.000 |
| PSEN1 | ENSP00000326366 | 5.000 |
| APOE | ENSP00000252486 | 5.000 |
| TREM2 | ENSP00000362205 | 4.825 |
| ... | ... | ... |
| PTTG1 | ENSP00000377536 | 0.682 |
| ISL2 | ENSP00000290759 | 0.682 |
| hsa-miR-4433b-3p | hsa-miR-4433b-3p | 0.682 |
| NEURL1B | ENSP00000358815 | 0.681 |
| SLC26A4 | ENSP00000494017 | 0.681 |
10000 rows × 2 columns
only by model#
Only by model which were significant#
Only significant by RSN#
mask = (scores_common[(str(args.baseline), 'rejected')] & mask_different)
mask.sum()