Variational Autoencoder#
pimmslearn - INFO Experiment 03 - Analysis of latent spaces and performance comparisions
Papermill script parameters:
# files and folders
# Datasplit folder with data for experiment
folder_experiment: str = 'runs/example'
folder_data: str = '' # specify data directory if needed
file_format: str = 'csv' # file format of create splits, default pickle (pkl)
# Machine parsed metadata from rawfile workflow
fn_rawfile_metadata: str = 'data/dev_datasets/HeLa_6070/files_selected_metadata_N50.csv'
# training
epochs_max: int = 50 # Maximum number of epochs
batch_size: int = 64 # Batch size for training (and evaluation)
cuda: bool = True # Whether to use a GPU for training
# model
# Dimensionality of encoding dimension (latent space of model)
latent_dim: int = 25
# A underscore separated string of layers, '256_128' for the encoder, reverse will be use for decoder
hidden_layers: str = '256_128'
# force_train:bool = True # Force training when saved model could be used. Per default re-train model
patience: int = 50 # Patience for early stopping
sample_idx_position: int = 0 # position of index which is sample ID
model: str = 'VAE' # model name
model_key: str = 'VAE' # potentially alternative key for model (grid search)
save_pred_real_na: bool = True # Save all predictions for missing values
# metadata -> defaults for metadata extracted from machine data
meta_date_col: str = None # date column in meta data
meta_cat_col: str = None # category column in meta data
# Parameters
model = "VAE"
latent_dim = 10
batch_size = 64
epochs_max = 300
hidden_layers = "64"
sample_idx_position = 0
cuda = False
save_pred_real_na = True
fn_rawfile_metadata = "https://raw.githubusercontent.com/RasmussenLab/njab/HEAD/docs/tutorial/data/alzheimer/meta.csv"
folder_experiment = "runs/alzheimer_study"
model_key = "VAE"
Some argument transformations
{'folder_experiment': 'runs/alzheimer_study',
'folder_data': '',
'file_format': 'csv',
'fn_rawfile_metadata': 'https://raw.githubusercontent.com/RasmussenLab/njab/HEAD/docs/tutorial/data/alzheimer/meta.csv',
'epochs_max': 300,
'batch_size': 64,
'cuda': False,
'latent_dim': 10,
'hidden_layers': '64',
'patience': 50,
'sample_idx_position': 0,
'model': 'VAE',
'model_key': 'VAE',
'save_pred_real_na': True,
'meta_date_col': None,
'meta_cat_col': None}
{'batch_size': 64,
'cuda': False,
'data': Path('runs/alzheimer_study/data'),
'epochs_max': 300,
'file_format': 'csv',
'fn_rawfile_metadata': 'https://raw.githubusercontent.com/RasmussenLab/njab/HEAD/docs/tutorial/data/alzheimer/meta.csv',
'folder_data': '',
'folder_experiment': Path('runs/alzheimer_study'),
'hidden_layers': [64],
'latent_dim': 10,
'meta_cat_col': None,
'meta_date_col': None,
'model': 'VAE',
'model_key': 'VAE',
'out_figures': Path('runs/alzheimer_study/figures'),
'out_folder': Path('runs/alzheimer_study'),
'out_metrics': Path('runs/alzheimer_study'),
'out_models': Path('runs/alzheimer_study'),
'out_preds': Path('runs/alzheimer_study/preds'),
'patience': 50,
'sample_idx_position': 0,
'save_pred_real_na': True}
Some naming conventions
Load data in long format#
pimmslearn.io.datasplits - INFO Loaded 'train_X' from file: runs/alzheimer_study/data/train_X.csv
pimmslearn.io.datasplits - INFO Loaded 'val_y' from file: runs/alzheimer_study/data/val_y.csv
pimmslearn.io.datasplits - INFO Loaded 'test_y' from file: runs/alzheimer_study/data/test_y.csv
data is loaded in long format
Sample ID protein groups
Sample_140 Q96S96 19.588
Sample_127 O14498 20.153
Sample_060 P54802 17.842
Sample_143 Q16769 19.584
Sample_180 Q8IW52 15.998
Name: intensity, dtype: float64
Infer index names from long format
pimmslearn - INFO sample_id = 'Sample ID', single feature: index_column = 'protein groups'
load meta data for splits
| _collection site | _age at CSF collection | _gender | _t-tau [ng/L] | _p-tau [ng/L] | _Abeta-42 [ng/L] | _Abeta-40 [ng/L] | _Abeta-42/Abeta-40 ratio | _primary biochemical AD classification | _clinical AD diagnosis | _MMSE score | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Sample ID | |||||||||||
| Sample_000 | Sweden | 71.000 | f | 703.000 | 85.000 | 562.000 | NaN | NaN | biochemical control | NaN | NaN |
| Sample_001 | Sweden | 77.000 | m | 518.000 | 91.000 | 334.000 | NaN | NaN | biochemical AD | NaN | NaN |
| Sample_002 | Sweden | 75.000 | m | 974.000 | 87.000 | 515.000 | NaN | NaN | biochemical AD | NaN | NaN |
| Sample_003 | Sweden | 72.000 | f | 950.000 | 109.000 | 394.000 | NaN | NaN | biochemical AD | NaN | NaN |
| Sample_004 | Sweden | 63.000 | f | 873.000 | 88.000 | 234.000 | NaN | NaN | biochemical AD | NaN | NaN |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| Sample_205 | Berlin | 69.000 | f | 1,945.000 | NaN | 699.000 | 12,140.000 | 0.058 | biochemical AD | AD | 17.000 |
| Sample_206 | Berlin | 73.000 | m | 299.000 | NaN | 1,420.000 | 16,571.000 | 0.086 | biochemical control | non-AD | 28.000 |
| Sample_207 | Berlin | 71.000 | f | 262.000 | NaN | 639.000 | 9,663.000 | 0.066 | biochemical control | non-AD | 28.000 |
| Sample_208 | Berlin | 83.000 | m | 289.000 | NaN | 1,436.000 | 11,285.000 | 0.127 | biochemical control | non-AD | 24.000 |
| Sample_209 | Berlin | 63.000 | f | 591.000 | NaN | 1,299.000 | 11,232.000 | 0.116 | biochemical control | non-AD | 29.000 |
210 rows × 11 columns
Initialize Comparison#
replicates idea for truely missing values: Define truth as by using n=3 replicates to impute each sample
real test data:
Not used for predictions or early stopping.
[x] add some additional NAs based on distribution of data
protein groups
A0A024QZX5;A0A087X1N8;P35237 197
A0A024R0T9;K7ER74;P02655 208
A0A024R3W6;A0A024R412;O60462;O60462-2;O60462-3;O60462-4;O60462-5;Q7LBX6;X5D2Q8 185
A0A024R644;A0A0A0MRU5;A0A1B0GWI2;O75503 208
A0A075B6H7 97
Name: freq, dtype: int64
Produce some addional simulated samples#
The validation simulated NA is used to by all models to evaluate training performance.
| observed | ||
|---|---|---|
| Sample ID | protein groups | |
| Sample_158 | Q9UN70;Q9UN70-2 | 14.630 |
| Sample_050 | Q9Y287 | 15.755 |
| Sample_107 | Q8N475;Q8N475-2 | 15.029 |
| Sample_199 | P06307 | 19.376 |
| Sample_067 | Q5VUB5 | 15.309 |
| ... | ... | ... |
| Sample_111 | F6SYF8;Q9UBP4 | 22.822 |
| Sample_002 | A0A0A0MT36 | 18.165 |
| Sample_049 | Q8WY21;Q8WY21-2;Q8WY21-3;Q8WY21-4 | 15.525 |
| Sample_182 | Q8NFT8 | 14.379 |
| Sample_123 | Q16853;Q16853-2 | 14.504 |
12600 rows × 1 columns
| observed | |
|---|---|
| count | 12,600.000 |
| mean | 16.339 |
| std | 2.741 |
| min | 7.209 |
| 25% | 14.412 |
| 50% | 15.935 |
| 75% | 17.910 |
| max | 30.140 |
Data in wide format#
Autoencoder need data in wide format
| protein groups | A0A024QZX5;A0A087X1N8;P35237 | A0A024R0T9;K7ER74;P02655 | A0A024R3W6;A0A024R412;O60462;O60462-2;O60462-3;O60462-4;O60462-5;Q7LBX6;X5D2Q8 | A0A024R644;A0A0A0MRU5;A0A1B0GWI2;O75503 | A0A075B6H7 | A0A075B6H9 | A0A075B6I0 | A0A075B6I1 | A0A075B6I6 | A0A075B6I9 | ... | Q9Y653;Q9Y653-2;Q9Y653-3 | Q9Y696 | Q9Y6C2 | Q9Y6N6 | Q9Y6N7;Q9Y6N7-2;Q9Y6N7-4 | Q9Y6R7 | Q9Y6X5 | Q9Y6Y8;Q9Y6Y8-2 | Q9Y6Y9 | S4R3U6 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sample ID | |||||||||||||||||||||
| Sample_000 | 15.912 | 16.852 | 15.570 | 16.481 | 17.301 | 20.246 | 16.764 | 17.584 | 16.988 | 20.054 | ... | 16.012 | 15.178 | NaN | 15.050 | 16.842 | NaN | NaN | 19.563 | NaN | 12.805 |
| Sample_001 | NaN | 16.874 | 15.519 | 16.387 | NaN | 19.941 | 18.786 | 17.144 | NaN | 19.067 | ... | 15.528 | 15.576 | NaN | 14.833 | 16.597 | 20.299 | 15.556 | 19.386 | 13.970 | 12.442 |
| Sample_002 | 16.111 | NaN | 15.935 | 16.416 | 18.175 | 19.251 | 16.832 | 15.671 | 17.012 | 18.569 | ... | 15.229 | 14.728 | 13.757 | 15.118 | 17.440 | 19.598 | 15.735 | 20.447 | 12.636 | 12.505 |
| Sample_003 | 16.107 | 17.032 | 15.802 | 16.979 | 15.963 | 19.628 | 17.852 | 18.877 | 14.182 | 18.985 | ... | 15.495 | 14.590 | 14.682 | 15.140 | 17.356 | 19.429 | NaN | 20.216 | NaN | 12.445 |
| Sample_004 | 15.603 | 15.331 | 15.375 | 16.679 | NaN | 20.450 | 18.682 | 17.081 | 14.140 | 19.686 | ... | 14.757 | NaN | NaN | 15.256 | 17.075 | 19.582 | 15.328 | NaN | 13.145 | NaN |
5 rows × 1421 columns
Add interpolation performance#
Fill Validation data with potentially missing features#
| protein groups | A0A024QZX5;A0A087X1N8;P35237 | A0A024R0T9;K7ER74;P02655 | A0A024R3W6;A0A024R412;O60462;O60462-2;O60462-3;O60462-4;O60462-5;Q7LBX6;X5D2Q8 | A0A024R644;A0A0A0MRU5;A0A1B0GWI2;O75503 | A0A075B6H7 | A0A075B6H9 | A0A075B6I0 | A0A075B6I1 | A0A075B6I6 | A0A075B6I9 | ... | Q9Y653;Q9Y653-2;Q9Y653-3 | Q9Y696 | Q9Y6C2 | Q9Y6N6 | Q9Y6N7;Q9Y6N7-2;Q9Y6N7-4 | Q9Y6R7 | Q9Y6X5 | Q9Y6Y8;Q9Y6Y8-2 | Q9Y6Y9 | S4R3U6 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sample ID | |||||||||||||||||||||
| Sample_000 | 15.912 | 16.852 | 15.570 | 16.481 | 17.301 | 20.246 | 16.764 | 17.584 | 16.988 | 20.054 | ... | 16.012 | 15.178 | NaN | 15.050 | 16.842 | NaN | NaN | 19.563 | NaN | 12.805 |
| Sample_001 | NaN | 16.874 | 15.519 | 16.387 | NaN | 19.941 | 18.786 | 17.144 | NaN | 19.067 | ... | 15.528 | 15.576 | NaN | 14.833 | 16.597 | 20.299 | 15.556 | 19.386 | 13.970 | 12.442 |
| Sample_002 | 16.111 | NaN | 15.935 | 16.416 | 18.175 | 19.251 | 16.832 | 15.671 | 17.012 | 18.569 | ... | 15.229 | 14.728 | 13.757 | 15.118 | 17.440 | 19.598 | 15.735 | 20.447 | 12.636 | 12.505 |
| Sample_003 | 16.107 | 17.032 | 15.802 | 16.979 | 15.963 | 19.628 | 17.852 | 18.877 | 14.182 | 18.985 | ... | 15.495 | 14.590 | 14.682 | 15.140 | 17.356 | 19.429 | NaN | 20.216 | NaN | 12.445 |
| Sample_004 | 15.603 | 15.331 | 15.375 | 16.679 | NaN | 20.450 | 18.682 | 17.081 | 14.140 | 19.686 | ... | 14.757 | NaN | NaN | 15.256 | 17.075 | 19.582 | 15.328 | NaN | 13.145 | NaN |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| Sample_205 | 15.682 | 16.886 | 14.910 | 16.482 | NaN | 17.705 | 17.039 | NaN | 16.413 | 19.102 | ... | NaN | 15.684 | 14.236 | 15.415 | 17.551 | 17.922 | 16.340 | 19.928 | 12.929 | NaN |
| Sample_206 | 15.798 | 17.554 | 15.600 | 15.938 | NaN | 18.154 | 18.152 | 16.503 | 16.860 | 18.538 | ... | 15.422 | 16.106 | NaN | 15.345 | 17.084 | 18.708 | NaN | 19.433 | NaN | NaN |
| Sample_207 | 15.739 | NaN | 15.469 | 16.898 | NaN | 18.636 | 17.950 | 16.321 | 16.401 | 18.849 | ... | 15.808 | 16.098 | 14.403 | 15.715 | NaN | 18.725 | 16.138 | 19.599 | 13.637 | 11.174 |
| Sample_208 | 15.477 | 16.779 | 14.995 | 16.132 | NaN | 14.908 | NaN | NaN | 16.119 | 18.368 | ... | 15.157 | 16.712 | NaN | 14.640 | 16.533 | 19.411 | 15.807 | 19.545 | NaN | NaN |
| Sample_209 | NaN | 17.261 | 15.175 | 16.235 | NaN | 17.893 | 17.744 | 16.371 | 15.780 | 18.806 | ... | 15.237 | 15.652 | 15.211 | 14.205 | 16.749 | 19.275 | 15.732 | 19.577 | 11.042 | 11.791 |
210 rows × 1421 columns
| protein groups | A0A024QZX5;A0A087X1N8;P35237 | A0A024R0T9;K7ER74;P02655 | A0A024R3W6;A0A024R412;O60462;O60462-2;O60462-3;O60462-4;O60462-5;Q7LBX6;X5D2Q8 | A0A024R644;A0A0A0MRU5;A0A1B0GWI2;O75503 | A0A075B6H7 | A0A075B6H9 | A0A075B6I0 | A0A075B6I1 | A0A075B6I6 | A0A075B6I9 | ... | Q9Y653;Q9Y653-2;Q9Y653-3 | Q9Y696 | Q9Y6C2 | Q9Y6N6 | Q9Y6N7;Q9Y6N7-2;Q9Y6N7-4 | Q9Y6R7 | Q9Y6X5 | Q9Y6Y8;Q9Y6Y8-2 | Q9Y6Y9 | S4R3U6 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sample ID | |||||||||||||||||||||
| Sample_000 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | 19.863 | NaN | NaN | NaN | NaN |
| Sample_001 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| Sample_002 | NaN | 14.523 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| Sample_003 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| Sample_004 | NaN | NaN | NaN | NaN | 15.473 | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | 14.048 | NaN | NaN | NaN | NaN | 19.867 | NaN | 12.235 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| Sample_205 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 11.802 |
| Sample_206 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| Sample_207 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| Sample_208 | NaN | NaN | NaN | NaN | NaN | NaN | 17.530 | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| Sample_209 | 15.727 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
210 rows × 1419 columns
| protein groups | A0A024QZX5;A0A087X1N8;P35237 | A0A024R0T9;K7ER74;P02655 | A0A024R3W6;A0A024R412;O60462;O60462-2;O60462-3;O60462-4;O60462-5;Q7LBX6;X5D2Q8 | A0A024R644;A0A0A0MRU5;A0A1B0GWI2;O75503 | A0A075B6H7 | A0A075B6H9 | A0A075B6I0 | A0A075B6I1 | A0A075B6I6 | A0A075B6I9 | ... | Q9Y653;Q9Y653-2;Q9Y653-3 | Q9Y696 | Q9Y6C2 | Q9Y6N6 | Q9Y6N7;Q9Y6N7-2;Q9Y6N7-4 | Q9Y6R7 | Q9Y6X5 | Q9Y6Y8;Q9Y6Y8-2 | Q9Y6Y9 | S4R3U6 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sample ID | |||||||||||||||||||||
| Sample_000 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | 19.863 | NaN | NaN | NaN | NaN |
| Sample_001 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| Sample_002 | NaN | 14.523 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| Sample_003 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| Sample_004 | NaN | NaN | NaN | NaN | 15.473 | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | 14.048 | NaN | NaN | NaN | NaN | 19.867 | NaN | 12.235 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| Sample_205 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 11.802 |
| Sample_206 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| Sample_207 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| Sample_208 | NaN | NaN | NaN | NaN | NaN | NaN | 17.530 | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| Sample_209 | 15.727 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
210 rows × 1421 columns
Variational Autoencoder#
Analysis: DataLoaders, Model, transform#
Analysis: DataLoaders, Model#
VAE(
(encoder): Sequential(
(0): Linear(in_features=1421, out_features=64, bias=True)
(1): Dropout(p=0.2, inplace=False)
(2): BatchNorm1d(64, eps=1e-05, momentum=0.1, affine=True, bias=True, track_running_stats=True)
(3): LeakyReLU(negative_slope=0.1)
(4): Linear(in_features=64, out_features=20, bias=True)
)
(decoder): Sequential(
(0): Linear(in_features=10, out_features=64, bias=True)
(1): Dropout(p=0.2, inplace=False)
(2): BatchNorm1d(64, eps=1e-05, momentum=0.1, affine=True, bias=True, track_running_stats=True)
(3): LeakyReLU(negative_slope=0.1)
(4): Linear(in_features=64, out_features=2842, bias=True)
)
)
Training#
Start Fit
- before_fit : [TrainEvalCallback, Recorder, ProgressCallback, EarlyStoppingCallback]
Start Epoch Loop
- before_epoch : [Recorder, ProgressCallback]
Start Train
- before_train : [TrainEvalCallback, Recorder, ProgressCallback]
Start Batch Loop
- before_batch : [ModelAdapterVAE, CastToTensor]
- after_pred : [ModelAdapterVAE]
- after_loss : [ModelAdapterVAE]
- before_backward: []
- before_step : []
- after_step : []
- after_cancel_batch: []
- after_batch : [TrainEvalCallback, Recorder, ProgressCallback]
End Batch Loop
End Train
- after_cancel_train: [Recorder]
- after_train : [Recorder, ProgressCallback]
Start Valid
- before_validate: [TrainEvalCallback, Recorder, ProgressCallback]
Start Batch Loop
- **CBs same as train batch**: []
End Batch Loop
End Valid
- after_cancel_validate: [Recorder]
- after_validate : [Recorder, ProgressCallback]
End Epoch Loop
- after_cancel_epoch: []
- after_epoch : [Recorder, EarlyStoppingCallback]
End Fit
- after_cancel_fit: []
- after_fit : [ProgressCallback, EarlyStoppingCallback]
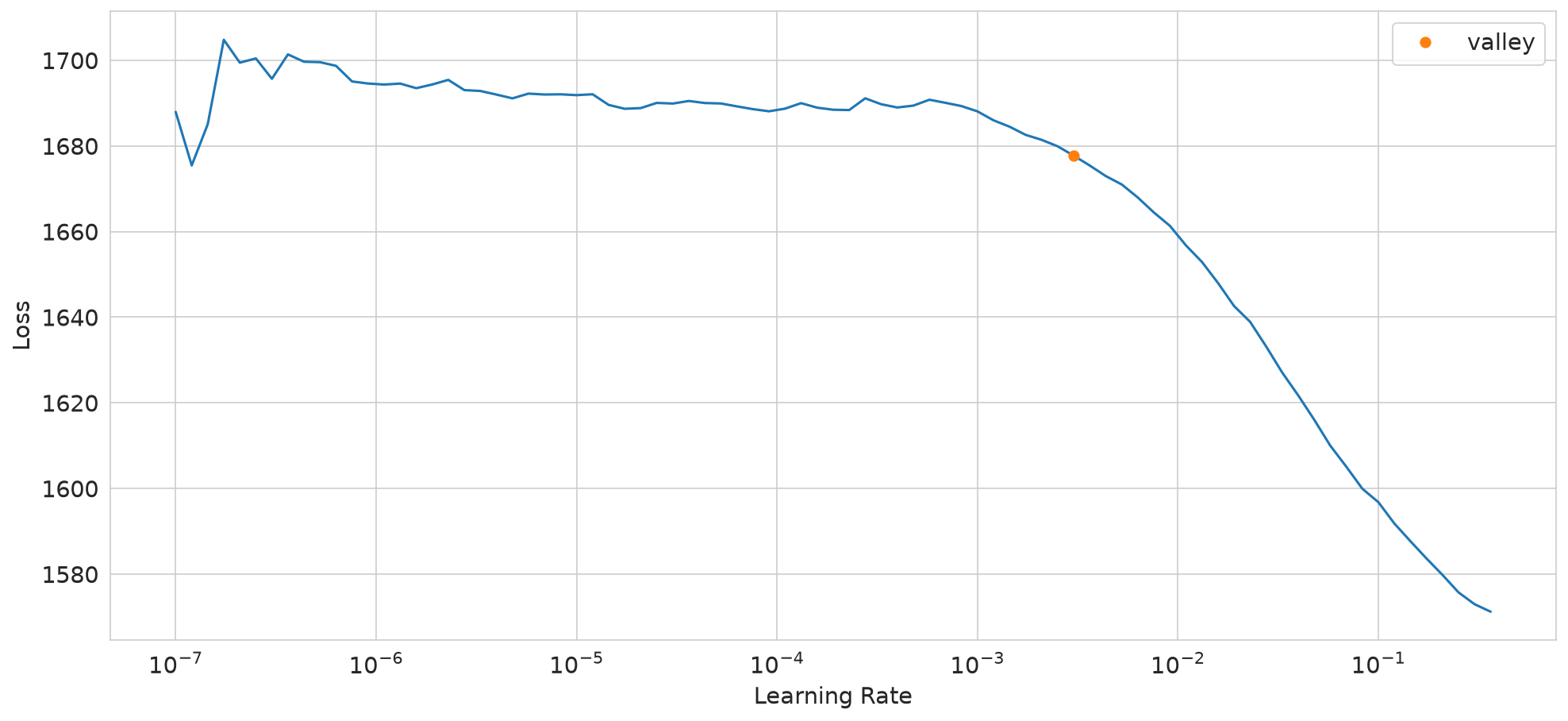
Adding a EarlyStoppingCallback results in an error. Potential fix in
PR3509 is not yet in
current version. Try again later
SuggestedLRs(valley=0.0030199517495930195)
dump model config
| epoch | train_loss | valid_loss | time |
|---|---|---|---|
| 0 | 1687.690063 | 92.853897 | 00:00 |
| 1 | 1684.072021 | 94.253754 | 00:00 |
| 2 | 1682.008545 | 93.654343 | 00:00 |
| 3 | 1680.848022 | 94.276993 | 00:00 |
| 4 | 1677.843262 | 94.543213 | 00:00 |
| 5 | 1674.314209 | 94.483749 | 00:00 |
| 6 | 1671.795410 | 95.606239 | 00:00 |
| 7 | 1668.650391 | 94.714317 | 00:00 |
| 8 | 1664.342041 | 94.447678 | 00:00 |
| 9 | 1661.116821 | 94.811409 | 00:00 |
| 10 | 1658.250610 | 94.286163 | 00:00 |
| 11 | 1654.668091 | 94.680588 | 00:00 |
| 12 | 1652.127563 | 94.857422 | 00:00 |
| 13 | 1647.596558 | 94.615448 | 00:00 |
| 14 | 1643.616455 | 94.526794 | 00:00 |
| 15 | 1639.167236 | 94.321518 | 00:00 |
| 16 | 1635.758911 | 93.897591 | 00:00 |
| 17 | 1631.248657 | 94.201653 | 00:00 |
| 18 | 1626.358276 | 93.568756 | 00:00 |
| 19 | 1620.609131 | 93.316338 | 00:00 |
| 20 | 1615.250610 | 93.887321 | 00:00 |
| 21 | 1608.340210 | 93.022896 | 00:00 |
| 22 | 1602.393188 | 93.212524 | 00:00 |
| 23 | 1595.197998 | 92.748955 | 00:00 |
| 24 | 1587.932129 | 92.617218 | 00:00 |
| 25 | 1579.862427 | 92.455856 | 00:00 |
| 26 | 1571.290405 | 92.446465 | 00:00 |
| 27 | 1561.633789 | 92.426659 | 00:00 |
| 28 | 1553.348511 | 92.766273 | 00:00 |
| 29 | 1542.468750 | 92.917358 | 00:00 |
| 30 | 1531.960083 | 92.627068 | 00:00 |
| 31 | 1521.738159 | 92.251694 | 00:00 |
| 32 | 1510.727905 | 92.465820 | 00:00 |
| 33 | 1499.094727 | 91.890121 | 00:00 |
| 34 | 1487.274780 | 92.090309 | 00:00 |
| 35 | 1476.110229 | 92.557198 | 00:00 |
| 36 | 1464.784668 | 92.736641 | 00:00 |
| 37 | 1453.802734 | 92.863693 | 00:00 |
| 38 | 1444.145508 | 93.311028 | 00:00 |
| 39 | 1433.271362 | 92.853676 | 00:00 |
| 40 | 1422.980225 | 93.517776 | 00:00 |
| 41 | 1411.958130 | 93.790619 | 00:00 |
| 42 | 1401.539917 | 93.531166 | 00:00 |
| 43 | 1391.165527 | 93.017197 | 00:00 |
| 44 | 1381.529785 | 92.615097 | 00:00 |
| 45 | 1370.921143 | 92.814789 | 00:00 |
| 46 | 1361.922363 | 92.267792 | 00:00 |
| 47 | 1351.974976 | 92.003693 | 00:00 |
| 48 | 1342.457275 | 91.327927 | 00:00 |
| 49 | 1333.360107 | 91.926071 | 00:00 |
| 50 | 1323.971924 | 92.287209 | 00:00 |
| 51 | 1316.353394 | 92.177658 | 00:00 |
| 52 | 1309.750000 | 91.305267 | 00:00 |
| 53 | 1302.246460 | 91.404045 | 00:00 |
| 54 | 1295.872559 | 91.496574 | 00:00 |
| 55 | 1288.320068 | 91.928032 | 00:00 |
| 56 | 1281.898438 | 91.848923 | 00:00 |
| 57 | 1274.719849 | 91.374931 | 00:00 |
| 58 | 1268.132080 | 91.358017 | 00:00 |
| 59 | 1263.293213 | 91.763466 | 00:00 |
| 60 | 1257.992065 | 91.418343 | 00:00 |
| 61 | 1251.996948 | 91.021141 | 00:00 |
| 62 | 1247.211182 | 90.919334 | 00:00 |
| 63 | 1240.906372 | 91.148483 | 00:00 |
| 64 | 1236.417358 | 91.044113 | 00:00 |
| 65 | 1231.177490 | 90.869568 | 00:00 |
| 66 | 1226.341064 | 90.813431 | 00:00 |
| 67 | 1220.830688 | 90.359451 | 00:00 |
| 68 | 1215.408691 | 90.782143 | 00:00 |
| 69 | 1211.099487 | 90.637329 | 00:00 |
| 70 | 1208.188110 | 90.580917 | 00:00 |
| 71 | 1204.232544 | 90.758720 | 00:00 |
| 72 | 1199.649414 | 90.929260 | 00:00 |
| 73 | 1194.221069 | 90.767067 | 00:00 |
| 74 | 1189.766846 | 90.478180 | 00:00 |
| 75 | 1185.052490 | 90.395721 | 00:00 |
| 76 | 1181.417480 | 90.613792 | 00:00 |
| 77 | 1176.756226 | 90.217949 | 00:00 |
| 78 | 1172.523560 | 90.441696 | 00:00 |
| 79 | 1168.366699 | 90.840851 | 00:00 |
| 80 | 1166.126831 | 91.061554 | 00:00 |
| 81 | 1161.902954 | 90.962173 | 00:00 |
| 82 | 1158.528198 | 91.296844 | 00:00 |
| 83 | 1157.384033 | 91.697533 | 00:00 |
| 84 | 1154.165405 | 91.800049 | 00:00 |
| 85 | 1151.832886 | 91.743706 | 00:00 |
| 86 | 1148.914429 | 91.072235 | 00:00 |
| 87 | 1145.506592 | 91.132202 | 00:00 |
| 88 | 1142.072876 | 91.205467 | 00:00 |
| 89 | 1140.492188 | 90.984337 | 00:00 |
| 90 | 1135.829712 | 90.698921 | 00:00 |
| 91 | 1133.213867 | 90.819473 | 00:00 |
| 92 | 1131.597534 | 90.890831 | 00:00 |
| 93 | 1127.713623 | 90.612862 | 00:00 |
| 94 | 1124.663452 | 90.696167 | 00:00 |
| 95 | 1121.846924 | 90.566162 | 00:00 |
| 96 | 1119.002808 | 90.506332 | 00:00 |
| 97 | 1116.055176 | 90.827263 | 00:00 |
| 98 | 1112.790405 | 90.975975 | 00:00 |
| 99 | 1110.860229 | 91.092041 | 00:00 |
| 100 | 1106.851440 | 90.936577 | 00:00 |
| 101 | 1105.353882 | 91.020493 | 00:00 |
| 102 | 1103.032959 | 90.754257 | 00:00 |
| 103 | 1101.691650 | 91.482796 | 00:00 |
| 104 | 1099.664185 | 91.190804 | 00:00 |
| 105 | 1097.008423 | 91.477036 | 00:00 |
| 106 | 1095.709717 | 91.468277 | 00:00 |
| 107 | 1094.388428 | 91.769699 | 00:00 |
| 108 | 1091.720703 | 91.755775 | 00:00 |
| 109 | 1089.645386 | 91.468925 | 00:00 |
| 110 | 1087.975830 | 92.009521 | 00:00 |
| 111 | 1086.766724 | 91.988625 | 00:00 |
| 112 | 1083.847656 | 92.180069 | 00:00 |
| 113 | 1082.315308 | 91.400108 | 00:00 |
| 114 | 1081.112305 | 91.625328 | 00:00 |
| 115 | 1079.576416 | 91.901672 | 00:00 |
| 116 | 1077.492310 | 92.045853 | 00:00 |
| 117 | 1075.705933 | 91.871468 | 00:00 |
| 118 | 1073.776733 | 92.004204 | 00:00 |
| 119 | 1074.155518 | 92.318443 | 00:00 |
| 120 | 1072.533203 | 92.266335 | 00:00 |
| 121 | 1072.517700 | 92.367157 | 00:00 |
| 122 | 1071.231079 | 92.370911 | 00:00 |
| 123 | 1070.232178 | 92.277496 | 00:00 |
| 124 | 1068.897827 | 92.229790 | 00:00 |
| 125 | 1068.957642 | 91.922592 | 00:00 |
| 126 | 1067.020874 | 91.758888 | 00:00 |
| 127 | 1066.698242 | 91.621353 | 00:00 |
No improvement since epoch 77: early stopping
Save number of actually trained epochs
128
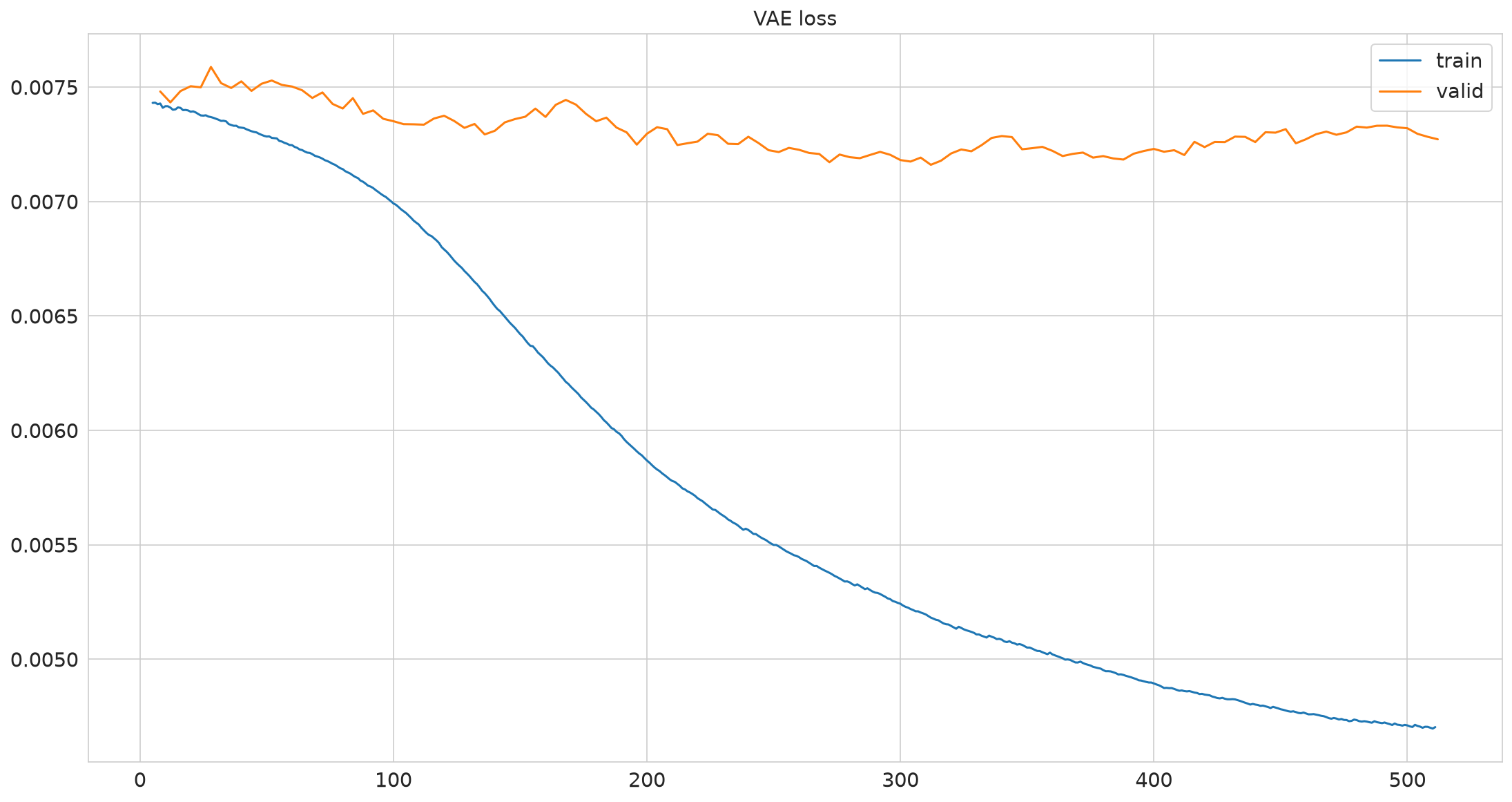
Loss normalized by total number of measurements#
pimmslearn.plotting - INFO Saved Figures to runs/alzheimer_study/figures/vae_training
Predictions#
create predictions and select validation data predictions
Sample ID protein groups
Sample_000 A0A024QZX5;A0A087X1N8;P35237 15.944
A0A024R0T9;K7ER74;P02655 16.778
A0A024R3W6;A0A024R412;O60462;O60462-2;O60462-3;O60462-4;O60462-5;Q7LBX6;X5D2Q8 15.807
A0A024R644;A0A0A0MRU5;A0A1B0GWI2;O75503 16.743
A0A075B6H7 17.329
...
Sample_209 Q9Y6R7 19.171
Q9Y6X5 15.961
Q9Y6Y8;Q9Y6Y8-2 19.710
Q9Y6Y9 11.879
S4R3U6 11.448
Length: 298410, dtype: float32
| observed | VAE | ||
|---|---|---|---|
| Sample ID | protein groups | ||
| Sample_158 | Q9UN70;Q9UN70-2 | 14.630 | 15.598 |
| Sample_050 | Q9Y287 | 15.755 | 16.879 |
| Sample_107 | Q8N475;Q8N475-2 | 15.029 | 14.352 |
| Sample_199 | P06307 | 19.376 | 19.046 |
| Sample_067 | Q5VUB5 | 15.309 | 15.046 |
| ... | ... | ... | ... |
| Sample_111 | F6SYF8;Q9UBP4 | 22.822 | 22.925 |
| Sample_002 | A0A0A0MT36 | 18.165 | 16.001 |
| Sample_049 | Q8WY21;Q8WY21-2;Q8WY21-3;Q8WY21-4 | 15.525 | 15.407 |
| Sample_182 | Q8NFT8 | 14.379 | 13.615 |
| Sample_123 | Q16853;Q16853-2 | 14.504 | 14.488 |
12600 rows × 2 columns
| observed | VAE | ||
|---|---|---|---|
| Sample ID | protein groups | ||
| Sample_000 | A0A075B6P5;P01615 | 17.016 | 17.316 |
| A0A087X089;Q16627;Q16627-2 | 18.280 | 18.197 | |
| A0A0B4J2B5;S4R460 | 21.735 | 22.292 | |
| A0A140T971;O95865;Q5SRR8;Q5SSV3 | 14.603 | 15.275 | |
| A0A140TA33;A0A140TA41;A0A140TA52;P22105;P22105-3;P22105-4 | 16.143 | 16.844 | |
| ... | ... | ... | ... |
| Sample_209 | Q96ID5 | 16.074 | 16.154 |
| Q9H492;Q9H492-2 | 13.173 | 13.393 | |
| Q9HC57 | 14.207 | 13.975 | |
| Q9NPH3;Q9NPH3-2;Q9NPH3-5 | 14.962 | 15.077 | |
| Q9UGM5;Q9UGM5-2 | 16.871 | 16.471 |
12600 rows × 2 columns
save missing values predictions
Sample ID protein groups
Sample_000 A0A075B6J9 15.720
A0A075B6Q5 15.832
A0A075B6R2 16.975
A0A075B6S5 16.327
A0A087WSY4 16.405
...
Sample_209 Q9P1W8;Q9P1W8-2;Q9P1W8-4 16.208
Q9UI40;Q9UI40-2 16.392
Q9UIW2 16.629
Q9UMX0;Q9UMX0-2;Q9UMX0-4 13.372
Q9UP79 15.961
Name: intensity, Length: 46401, dtype: float32
Plots#
validation data
| latent dimension 1 | latent dimension 2 | latent dimension 3 | latent dimension 4 | latent dimension 5 | latent dimension 6 | latent dimension 7 | latent dimension 8 | latent dimension 9 | latent dimension 10 | |
|---|---|---|---|---|---|---|---|---|---|---|
| Sample ID | ||||||||||
| Sample_000 | -0.402 | -2.382 | 2.161 | -0.388 | -0.181 | 0.384 | -0.172 | -0.856 | -0.324 | 1.218 |
| Sample_001 | -0.083 | -2.159 | 1.263 | -0.132 | 0.568 | -0.523 | 0.816 | 0.617 | 0.151 | 1.028 |
| Sample_002 | 0.370 | -2.081 | 0.907 | -0.741 | -1.677 | 0.112 | -0.894 | 0.577 | 1.805 | 1.780 |
| Sample_003 | 0.374 | -2.146 | 1.483 | -1.190 | -0.191 | 0.250 | -1.295 | 0.729 | 0.417 | 1.498 |
| Sample_004 | -0.022 | -2.219 | 1.783 | -0.520 | -0.401 | 0.196 | -0.493 | 0.796 | -0.723 | 0.524 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| Sample_205 | 0.256 | -2.932 | -1.082 | -0.217 | -1.455 | 1.739 | -0.546 | 0.346 | -0.071 | -0.383 |
| Sample_206 | -0.799 | -0.074 | -1.286 | 1.353 | -1.551 | -1.475 | 0.949 | -1.029 | 0.688 | 0.525 |
| Sample_207 | -1.423 | -2.442 | 0.636 | 2.176 | -1.026 | 1.148 | -0.439 | -1.272 | -0.742 | -1.433 |
| Sample_208 | -0.121 | -1.993 | -0.673 | 1.808 | -0.939 | -1.504 | 0.555 | 0.224 | 1.270 | -1.597 |
| Sample_209 | -0.293 | -1.581 | -1.173 | 0.956 | -0.700 | -1.652 | -1.576 | 0.970 | 1.368 | -0.781 |
210 rows × 10 columns
freq_val
1 12
2 18
3 50
4 82
5 108
Name: count, dtype: int64
| VAE | ||
|---|---|---|
| mean | count | |
| protein groups | ||
| A0A024QZX5;A0A087X1N8;P35237 | 0.122 | 7 |
| A0A024R0T9;K7ER74;P02655 | 1.329 | 4 |
| A0A024R3W6;A0A024R412;O60462;O60462-2;O60462-3;O60462-4;O60462-5;Q7LBX6;X5D2Q8 | 0.280 | 9 |
| A0A024R644;A0A0A0MRU5;A0A1B0GWI2;O75503 | 0.242 | 6 |
| A0A075B6H7 | 0.595 | 6 |
| ... | ... | ... |
| Q9Y6R7 | 0.353 | 10 |
| Q9Y6X5 | 0.288 | 7 |
| Q9Y6Y8;Q9Y6Y8-2 | 0.285 | 9 |
| Q9Y6Y9 | 0.372 | 15 |
| S4R3U6 | 0.482 | 24 |
1419 rows × 2 columns
| VAE | ||
|---|---|---|
| Sample ID | protein groups | |
| Sample_158 | Q9UN70;Q9UN70-2 | 0.968 |
| Sample_050 | Q9Y287 | 1.124 |
| Sample_107 | Q8N475;Q8N475-2 | -0.677 |
| Sample_199 | P06307 | -0.330 |
| Sample_067 | Q5VUB5 | -0.263 |
| ... | ... | ... |
| Sample_111 | F6SYF8;Q9UBP4 | 0.103 |
| Sample_002 | A0A0A0MT36 | -2.164 |
| Sample_049 | Q8WY21;Q8WY21-2;Q8WY21-3;Q8WY21-4 | -0.118 |
| Sample_182 | Q8NFT8 | -0.764 |
| Sample_123 | Q16853;Q16853-2 | -0.016 |
12600 rows × 1 columns
Comparisons#
Simulated NAs : Artificially created NAs. Some data was sampled and set explicitly to misssing before it was fed to the model for reconstruction.
Validation data#
all measured (identified, observed) peptides in validation data
The simulated NA for the validation step are real test data (not used for training nor early stopping)
Selected as truth to compare to: observed
{'VAE': {'MSE': 0.45593273844805987,
'MAE': 0.43189727793148736,
'N': 12600,
'prop': 1.0}}
Test Datasplit#
Selected as truth to compare to: observed
{'VAE': {'MSE': 0.48091149712742703,
'MAE': 0.436850015541966,
'N': 12600,
'prop': 1.0}}
Save all metrics as json
{ 'test_simulated_na': { 'VAE': { 'MAE': 0.436850015541966,
'MSE': 0.48091149712742703,
'N': 12600,
'prop': 1.0}},
'valid_simulated_na': { 'VAE': { 'MAE': 0.43189727793148736,
'MSE': 0.45593273844805987,
'N': 12600,
'prop': 1.0}}}
| subset | valid_simulated_na | test_simulated_na | |
|---|---|---|---|
| model | metric_name | ||
| VAE | MSE | 0.456 | 0.481 |
| MAE | 0.432 | 0.437 | |
| N | 12,600.000 | 12,600.000 | |
| prop | 1.000 | 1.000 |
Save predictions#
Config#
{}
{'M': 1421,
'batch_size': 64,
'cuda': False,
'data': Path('runs/alzheimer_study/data'),
'epoch_trained': 128,
'epochs_max': 300,
'file_format': 'csv',
'fn_rawfile_metadata': 'https://raw.githubusercontent.com/RasmussenLab/njab/HEAD/docs/tutorial/data/alzheimer/meta.csv',
'folder_data': '',
'folder_experiment': Path('runs/alzheimer_study'),
'hidden_layers': [64],
'latent_dim': 10,
'meta_cat_col': None,
'meta_date_col': None,
'model': 'VAE',
'model_key': 'VAE',
'n_params': 277998,
'out_figures': Path('runs/alzheimer_study/figures'),
'out_folder': Path('runs/alzheimer_study'),
'out_metrics': Path('runs/alzheimer_study'),
'out_models': Path('runs/alzheimer_study'),
'out_preds': Path('runs/alzheimer_study/preds'),
'patience': 50,
'sample_idx_position': 0,
'save_pred_real_na': True}